解きたい課題を設定したらその課題に必要なデータを用意します。良い予測モデルを作成するためにデータを収集したり、手元のデータを予測分析に利用できる形に整えたりします。
課題に合ったデータが入手できないとわかった場合は、課題設定をやり直すこともあります。
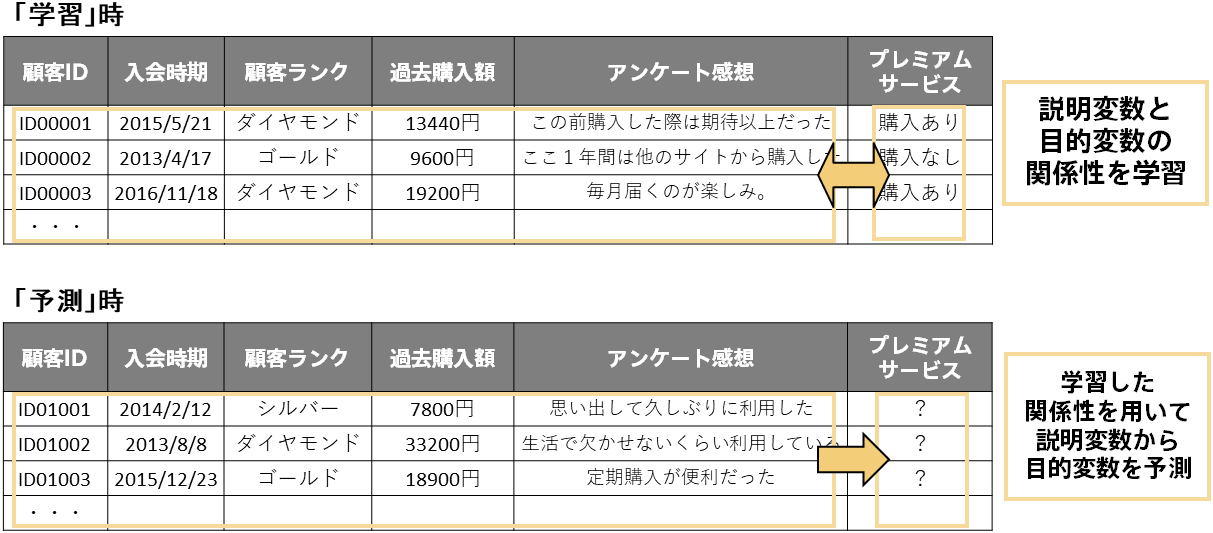
データが用意出来たらPrediction Oneに入力できる表形式に整えます。行は各レコードで列はそのレコードを説明する情報という1つの表です。例えば顧客データの場合は、行は各顧客で列はその顧客に関する情報(入会日、顧客ランク、など)です。
Prediction Oneには4つのデータタイプがあります。それは、日時・数値・文字列・テキストです。
| データタイプ | 説明 |
|---|---|
| 日時 | 日時データは標準的な日時フォーマットで入力された文字を日時情報として扱うことができるデータタイプです。対応している具体的なフォーマットは「データセットのより詳細な仕様」をご確認ください。 |
| 数値 | 数値データは文字通り数字を扱うデータタイプです。「2」「139.48」などがこれにあたります。この際、「13440円」のように単位がついていても問題ありません。 |
| 文字列 | 文字列データは、「プラチナ・ゴールド・シルバー」「あり・なし」などカテゴリを扱うデータタイプです |
| テキスト | テキストはアンケート回答など自然言語で入力された文章です。Prediction Oneは内部に英語と日本語の言語解析器をもっているため自然言語に対して特別な前処理をする必要はありません。自然言語から自動的に重要な情報を抽出して学習・予測に利用します。 |
また、列のうち1列は予測したい項目(目的変数)である必要があります。これは「1.2 予測分析で解きたい課題を設定する」で設定した課題に沿ってどれが予測したい項目なのか決まります。

Prediction Oneは入力されたデータに対してどのデータタイプが適切か自動で判別します。前処理では、すべての項目を数値に直さなければいけない、テキストからは事前に重要単語を抜き出しておかなければならない、といったことはありません。
また、値が欠損していても問題なく、欠損している場合は空文字列で表現してください。
どんなフォーマットでデータを用意すればよいか具体例が見たい場合は、「アップロード済みデータ一覧画面」にあるサンプルデータもぜひ参考にしてみてください。
行が各レコード、列がそれを説明する情報という形でデータを用意できなかった場合は以下も参考にしてください。
▶ 前処理で表形式データを用意出来なかった場合