データ準備機能で使用できる各データ加工ステップの処理内容の詳細を説明します。
集計やデータ結合など、ファイル全体に対して加工処理を実行します。
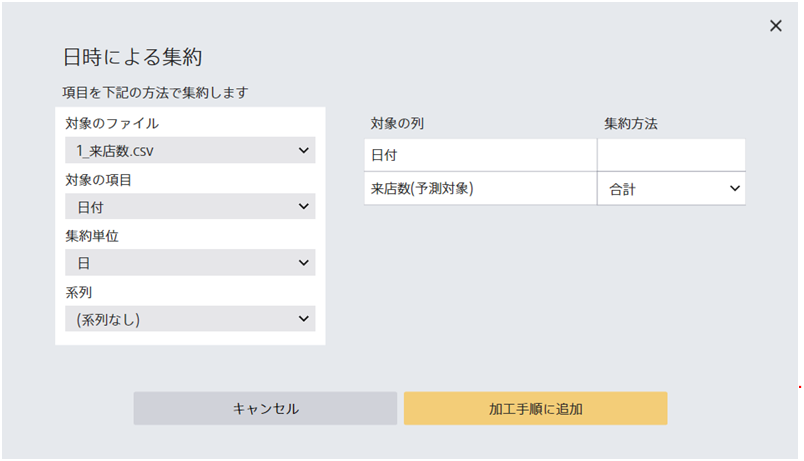
日時による集約は、日時型項目をもとにして日ごと・週ごと・月ごと・年ごとにデータを集約します。
指定できる集約方法は項目のデータタイプによって異なります。 数値型項目のみ合計・平均を指定できます。
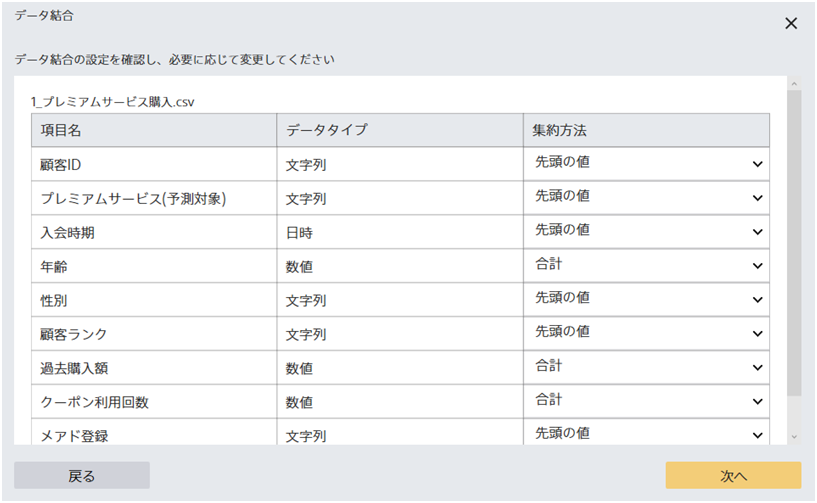
データ結合をする際に、複数の行をどのように集約するかを指定します。
特定のフォーマットのファイルを、時系列予測が可能な形に変換します。 日時と系列名が一行目・一列目に含まれている場合、ファイルを時系列予測が可能なフォーマットに変換します。

変換手順の詳細は時系列予測を実行できる形式に変換するをご確認ください。
指定した項目に加工を実行し、既存の項目のデータを上書きします。
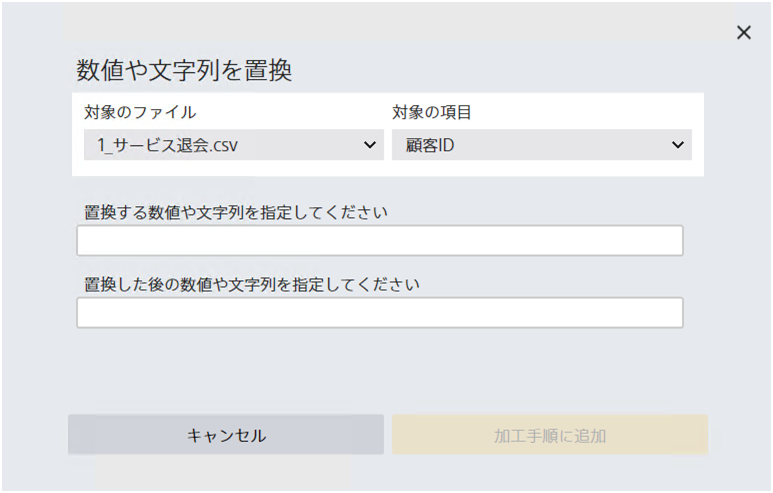
数値型・文字列型の項目にのみ適用でき、完全に一致する値が含まれる箇所を指定した数値・文字列に置換します。 部分一致による文字列の置換は「文字列の一部を置換」で実行できます。また、置換した後の文字列として空白は指定できません。
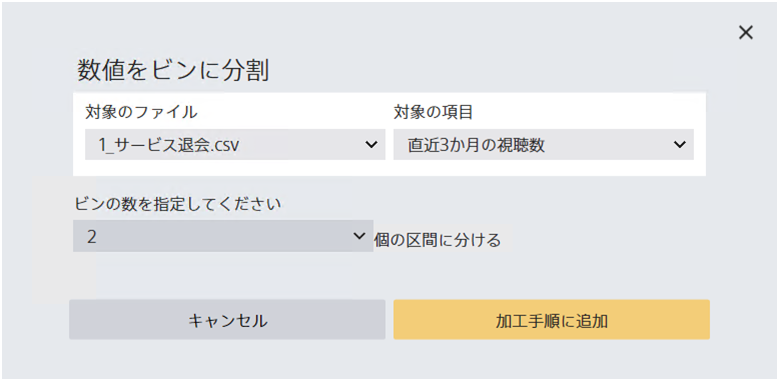
数値型項目を指定した数の区画(ビン数)に分割します。 ただし、ビン数が数値型項目のユニーク数を上回る場合はユニーク数よりも小さいビン数を自動的に指定します。
「数値をビンに分割」ではそれぞれのビンになるべく均等にデータが分かれるようにビンを作成します。そのため、ビンによって区間の幅が異なる場合があります。
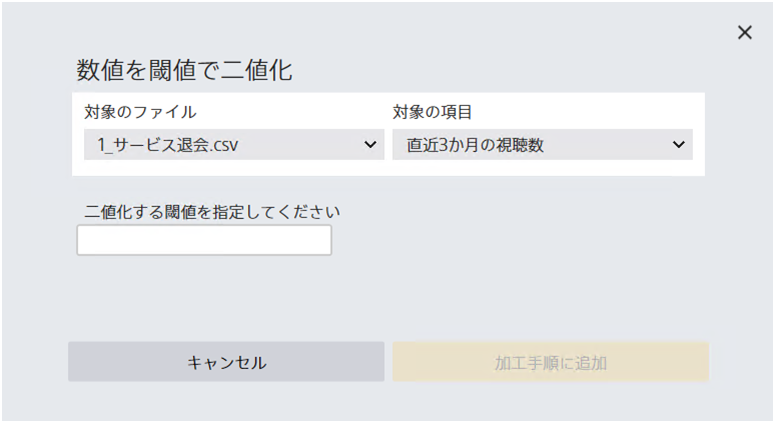
数値型項目が指定した閾値以上かどうか判定し、数値を『[指定した値]以上』、『[指定した値]より小さい』のどちらかの値に置換します。
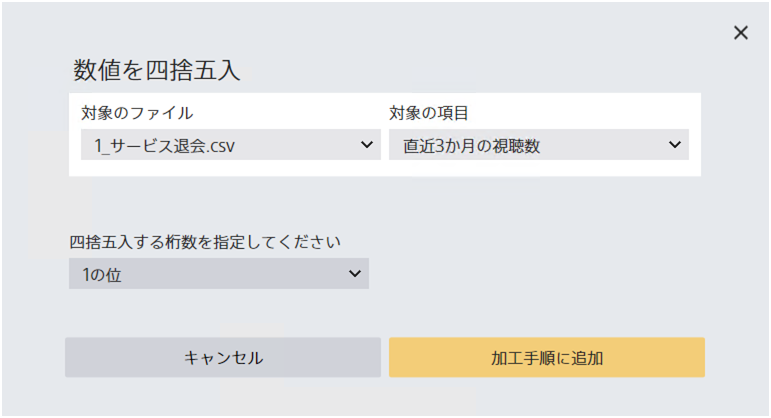
数値を指定された桁で四捨五入します。欠損値は無視されます。
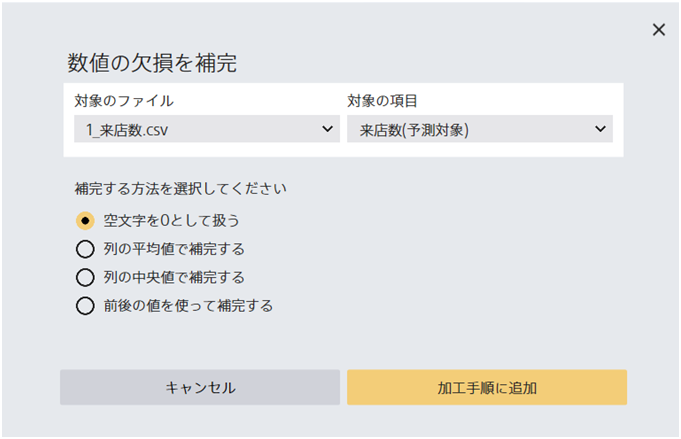
数値型項目の欠損を補完します。
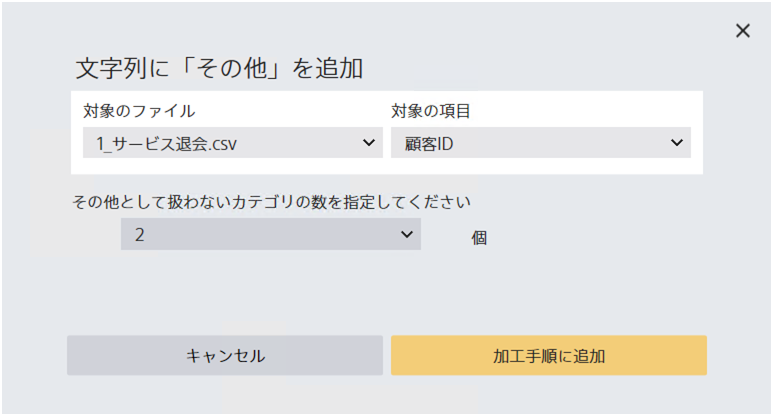
文字列型項目で、出現回数が少ない文字列を『その他』に置換します。 たとえば、『その他として扱わないカテゴリの数』として『2』を指定した場合、出現回数が3位以下である文字列をすべて『その他』に置換します。
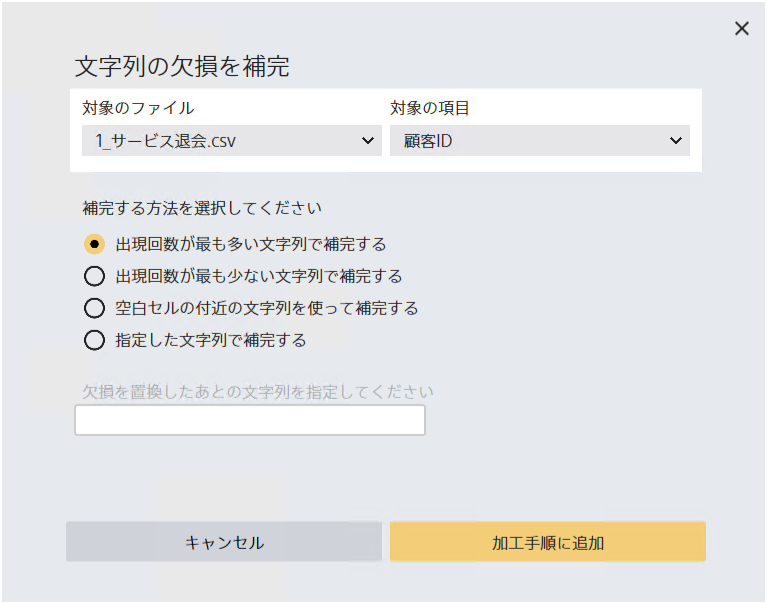
文字列型の項目にある欠損値を補間します。
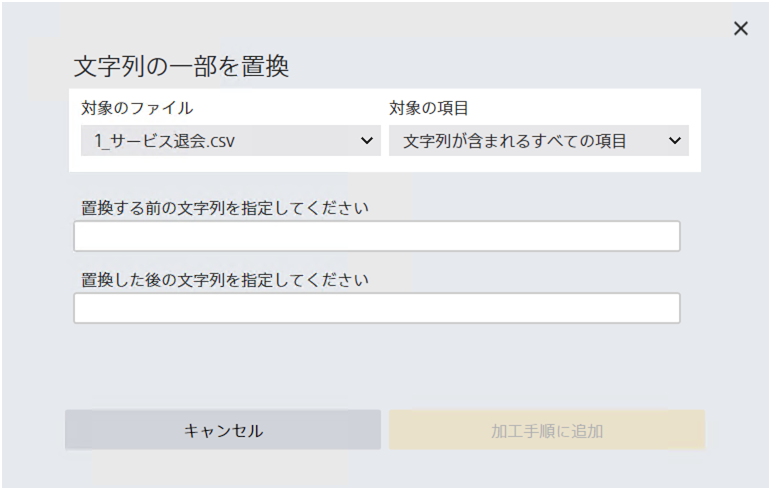
文字列の一部を置換できます。 完全一致による置換は「数値や文字列を置換」によって実行できます。
対象の項目として「文字列が含まれるすべての項目」を指定すると、ファイル中のすべての文字列型項目に対して置換を実行できます。
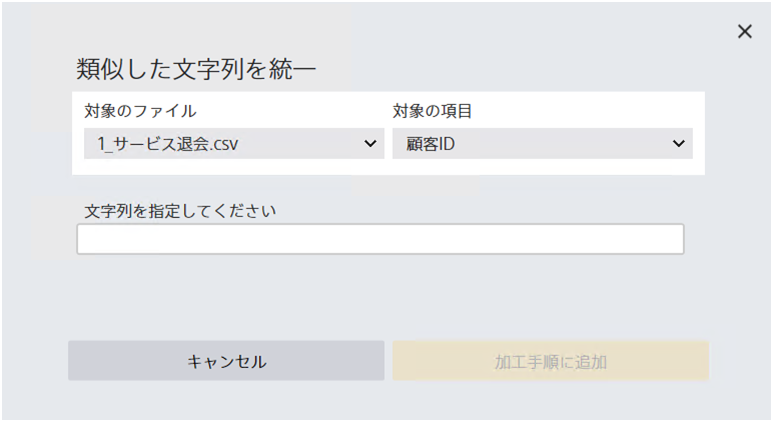
指定した文字列と共通する文字を含むかどうか判定し、共通する文字が多い場合は表記を統一します。 目安として7割以上の文字が共通している場合、表記を統一します。
指定した項目に加工を実行し、その結果得られた項目を新しく追加します。
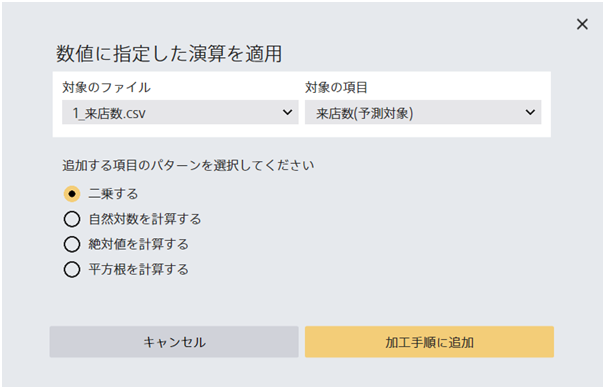
数値に指定した演算を適用します。平方根は0以上の数値のみ計算されます。 自然対数は0より大きい数値のみ計算されます。 範囲外の数値は欠損として処理されます。
 文字列・テキスト型の項目から数値を抽出します。
文字列・テキスト型の項目から数値を抽出します。
文字列を指定された記号・文字列で分割します。 該当する文字列が複数存在する場合、はじめに出現した文字列を基準にして分割します。
日時項目をもとに新しい項目を作成します。
住所が記録されているテキスト型の項目から、都道県名・市町村名を抽出した項目を作成します。 テキストは必ず都道府県名で始まっている必要があります。また、5文字以上の市町村名や「市」・「町」・「村」が市町村の名前に含まれている場合は抽出に失敗する場合があります。
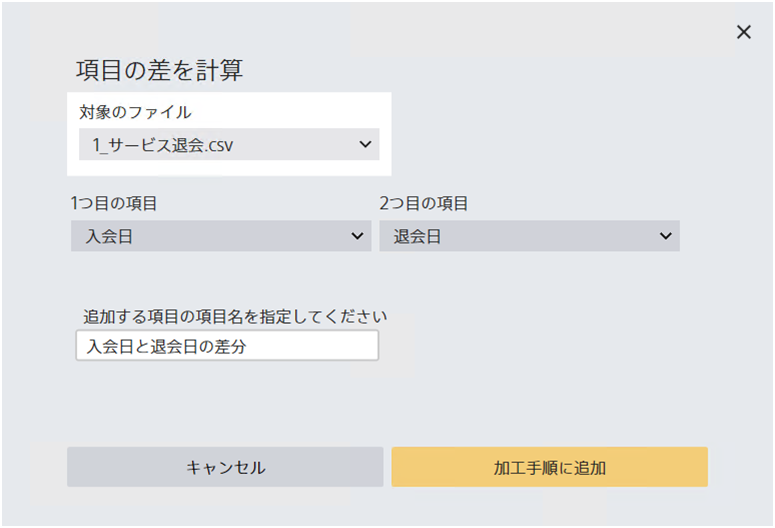
数値型・日時型の列の間の差を計算します。
指定された2つの項目のいずれかが欠損している・数値や日時に変換できない場合は結果は結果は欠損値になります。
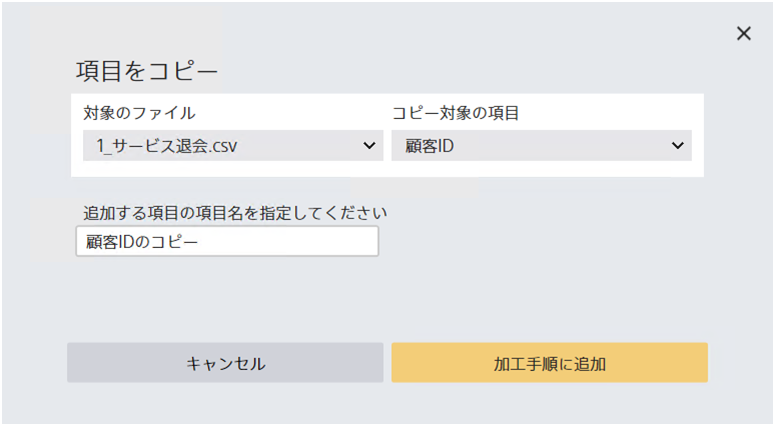
項目をコピーして追加します。
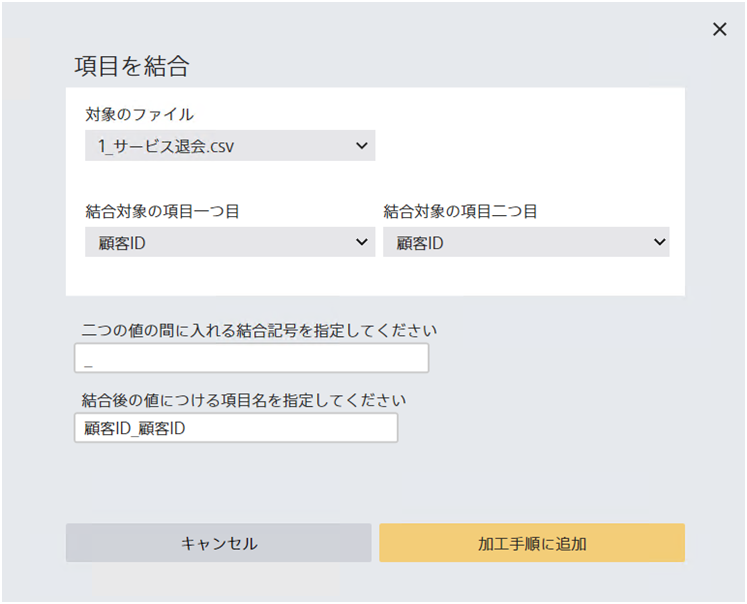
指定された二つの項目を結合し、あたらしく項目を追加します。
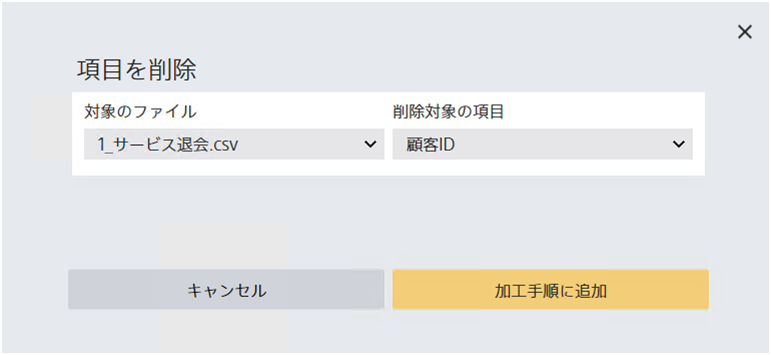
指定された項目を削除します。 削除した項目を再び加工に利用することはできません。
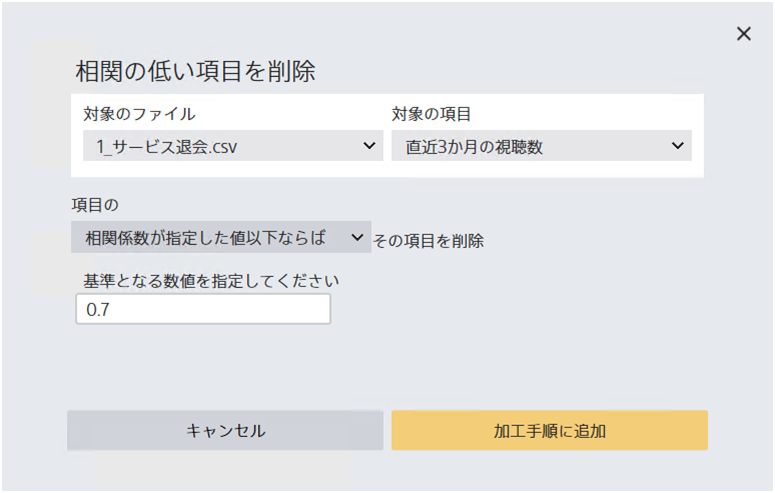
指定された数値型の項目との相関係数を計算し、相関係数が低い項目を削除します。 数値型でない項目は削除されません。
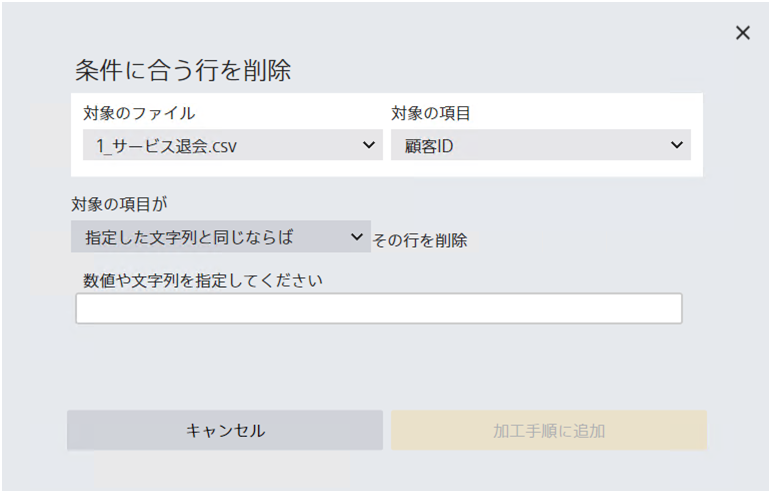
指定された条件にあてはまる行をファイルから削除します。 この加工処理は評価用データ・予測用データには適用されません。
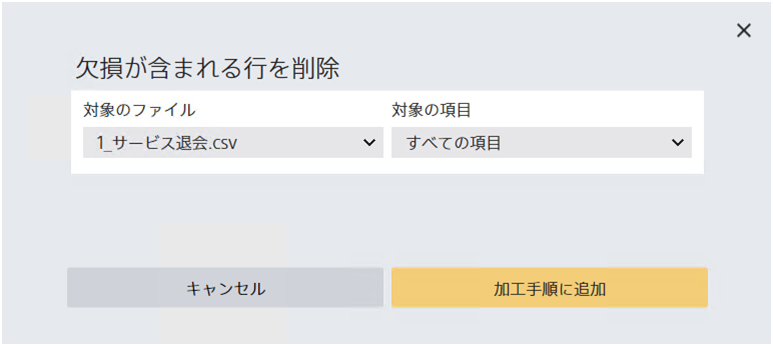
欠損が含まれる行をファイルから削除します。 この加工処理は評価用データ・予測用データには適用されません。
対象の項目として「すべての項目」が指定されている場合、行のいずれかにひとつでも欠損が存在するならばその行を削除します。
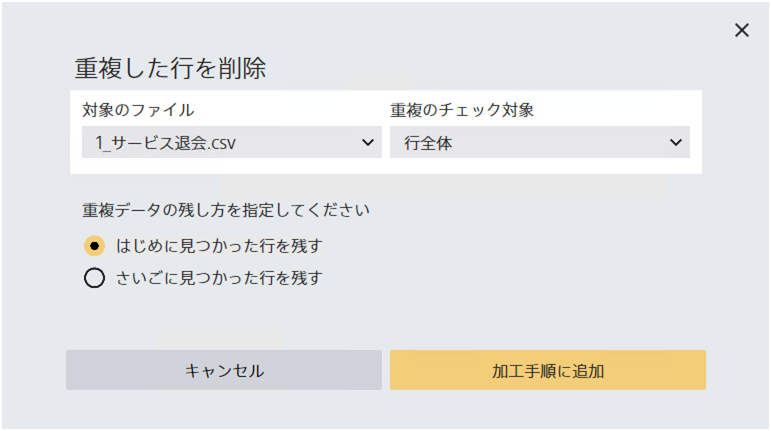
重複している行をひとつだけ残し、それ以外を削除します。項目を指定した場合、指定した項目に重複がある場合のみ削除されます。この加工処理は評価用データ・予測用データには適用されません。
対象の項目として「行全体」が指定されている場合、すべての項目が完全に一致している行が削除の対象になります。