Prediction Oneを使用して精度の良い予測モデルを作成するためには、良いデータを準備することが必要不可欠です。そのようなデータを準備するためには事前にデータをよく理解することが重要です。
データを理解するために活用できるのが、本資料で紹介するインサイト生成機能です。インサイト生成機能では自動でデータを可視化し、注目すべきインサイトを抽出します。本資料ではこの機能によってどのようなインサイトが作られるのか、どのような活用方法があるかをご説明します。
アプリ内での本機能の使用方法についてはインサイト生成機能の画面操作と説明をご参照ください。

インサイトはデータに関する様々な情報から構成されます。インサイトは以下の3種類があり、インサイト生成機能ではそれぞれ別のタブに表示されています。
各インサイトの内容は以下です。
「各項目の詳細」はデータに含まれる項目のうち設定画面で選択された項目一つずつについて基本情報、グラフによる可視化、データの改善点を示します。
「基本情報」は項目のデータの基本的な統計量をまとめたものです。インサイト生成機能に用いられる統計量は以下の通りです。
項目のデータタイプによって使用される統計量が異なります。以下の表を参照してください。
| 統計量名 | 文字列・日付・テキスト型 | 数値型 |
|---|---|---|
| データタイプ | 〇 | 〇 |
| ユニーク数 | 〇 | 〇 |
| ユニーク割合 | 〇 | 〇 |
| 欠損数 | 〇 | 〇 |
| 欠損割合 | 〇 | 〇 |
| 最大値 | × | 〇 |
| 最小値 | × | 〇 |
| 平均値 | × | 〇 |
| 中央値 | × | 〇 |
| 負の値の数 | × | 〇 |
| 負の値の割合 | × | 〇 |
項目ごとにデータのグラフとその説明文を表示します。項目のデータタイプによって作られるグラフの種類が異なります。
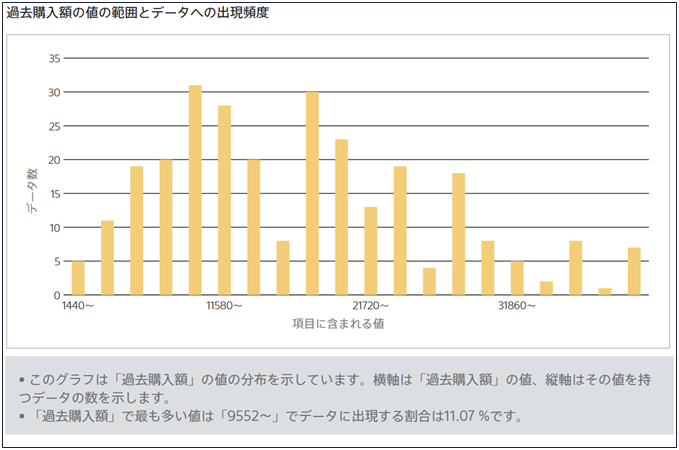
数値型の場合 (時系列モード不使用)
値の範囲を最大20個に区切り、その範囲内に含まれるデータの数を縦軸に取るようなヒストグラムを描画します。
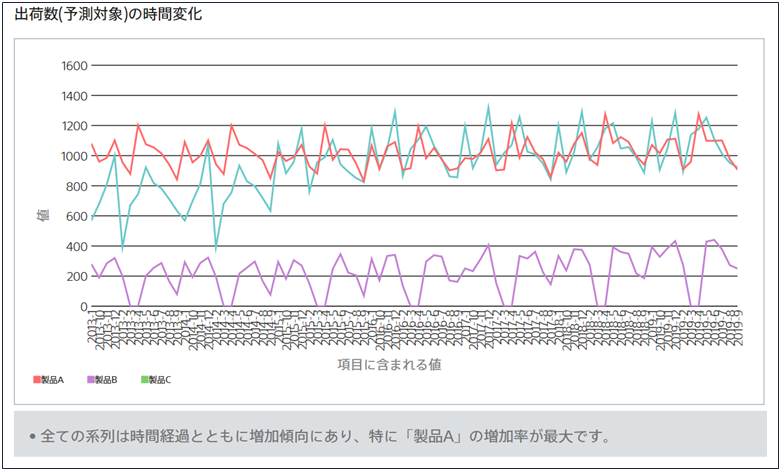
数値型の場合 (時系列モード使用)
横軸に時間情報、縦軸に予測したい項目の値をとった折れ線グラフを系列ごとに描画します。
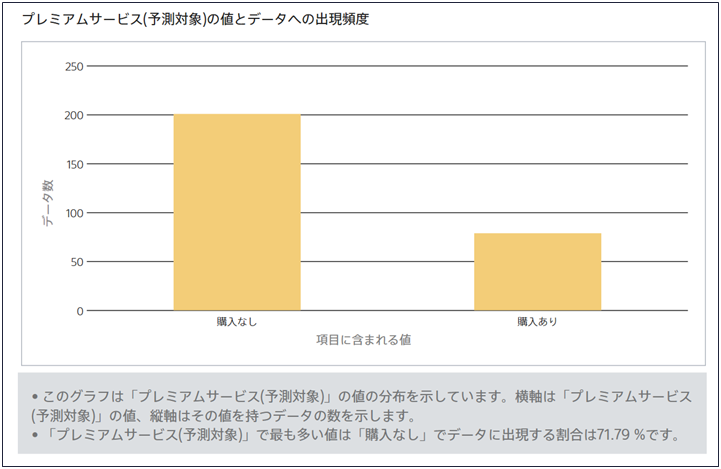
文字列・日付型の場合
値ごとに含まれるデータの数を縦軸に取るような棒グラフを描画します。値の種類が20を超える場合は頻度の低い値は<その他>にまとめられてカウントされます。
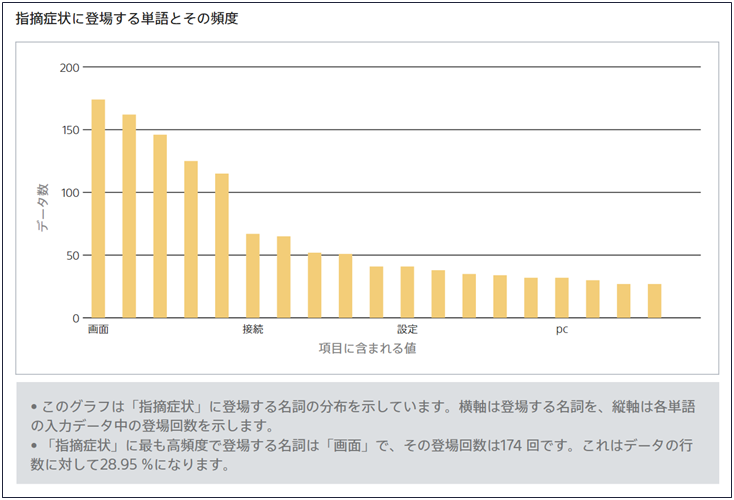
テキスト型の場合
テキスト型の列に含まれる文章を単語に分割し、単語のうち名詞の登場頻度を棒グラフで描画します。名詞の種類が20を超える場合は頻度の低いものは<その他>にまとめられてカウントされます。
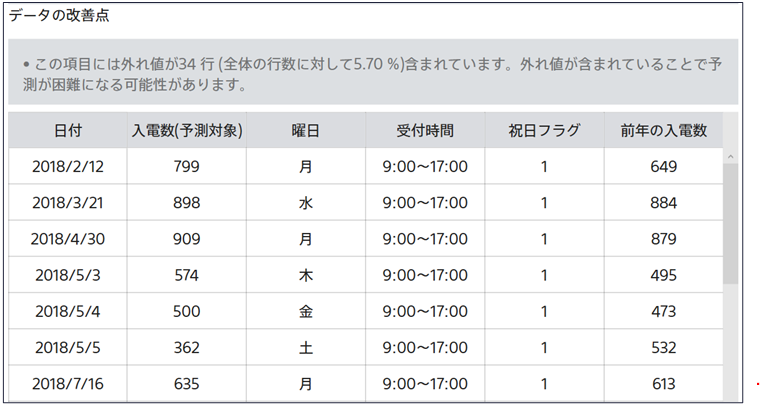
予測モデルを作成する際に精度を下げる要因になる点についてまとめたものです。以下の4種類のうち該当するものが表示されます。
外れ値
項目の値の中で他の値と大きく差がある値のことです。外れ値は正しく観測されたものの場合もありますが、例えば転記ミス等通常とは異なる方法で観測されたものである場合もあります。外れ値を含むデータでモデルを作成した場合、モデルが誤ったルールを学習してしまい予測精度に悪影響を及ぼす可能性があります。項目のデータ内に外れ値を含む場合、該当する行を表形式で表示します。
欠損
項目のデータのうち値が空文字であるものを欠損と呼びます。欠損が含まれていてもPrediction Oneではそれを特別な値として処理しモデルに学習させることができるので処理が不要な場合も多いです。しかし、何らかの異常で値が記録されなかった場合、モデルが期待通りにデータに関するルールを学習することができない可能性があるため、データを適切に処理する必要が出てきます。そのため、欠損割合が一定以上である場合、このデータの改善点を表示します。欠損についても該当する行を表形式で表示します。

ユニーク数
ユニーク割合が一定以上である場合にデータの改善点を表示します。データ数に対してユニークな値が多すぎると作成したモデルの予測精度に悪影響を及ぼす可能性があります。
値の偏り
予測対象の項目の分布に偏りがある場合にデータの改善点を表示します。ここでいう値の偏りというのは、極端にある値のデータ数が少なかったりすることを指します。データ数が極端に少ない値は十分に学習ができず予測が難しくなる可能性があります。
「項目間の関係」は予測した項目とそれ以外の入力項目との関係についてのインサイトをまとめたものです。以下の3種類があります。
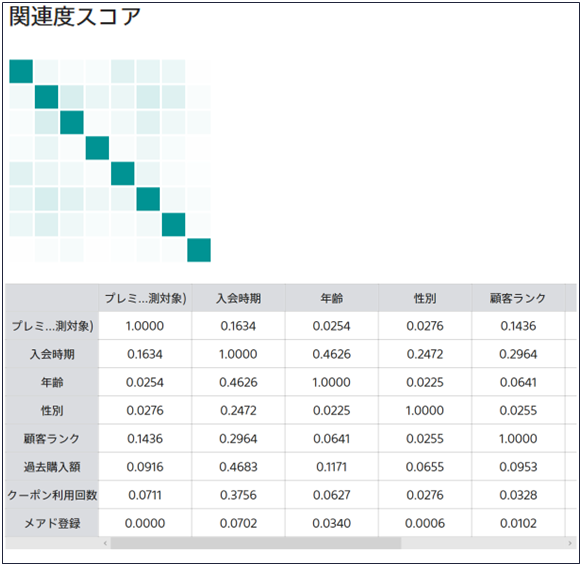
関連度スコアとは項目間の関連性の強さを表現した指標で、より具体的には相互情報量と呼ばれる値に項目のユニーク率を加味した係数をかけた指標です。0から1の間の値をとります。また、先頭1000行のデータから計算されます。
ヒートマップ上にカーソルを合わせると詳細が表示され、2つの項目とそれらの関連度の値が確認できます。またヒートマップの下には表形式で関連度スコアを確認することもできます。
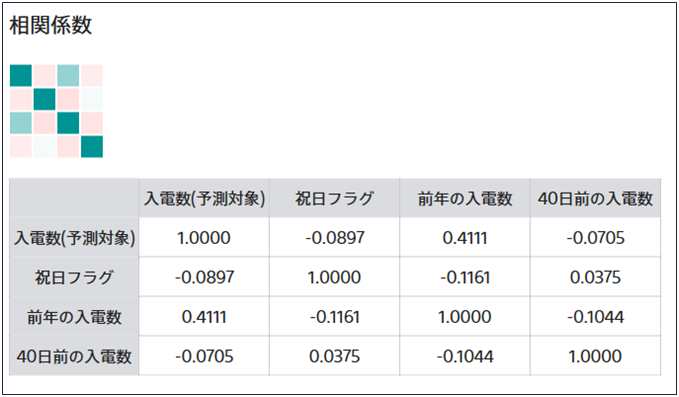
相関係数は2つの項目間の線形の関係を数値で表した指標で、-1から1の間の値をとります。1に近いほど正の相関が強く、0に近いほど相関が弱くなり、-1に近いほど負の相関が強いです。関連度スコアと同様、ヒートマップと表形式でその値を確認することができます。相関係数は数値型の項目同士でのみ計算されます。
2 つの項目間の関係を視覚的に確認するためにグラフを表示します。項目のデータタイプによって作成されるグラフの種類が異なります。
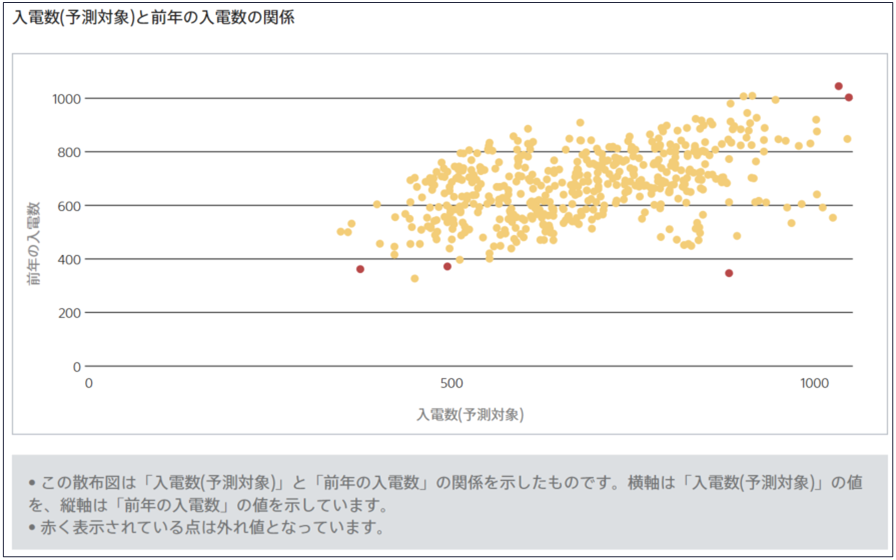
数値型x数値型
両方の項目が数値型の場合、散布図を描画します。最大で500 データまでプロットされます。赤いプロットは外れ値であることを示しています。
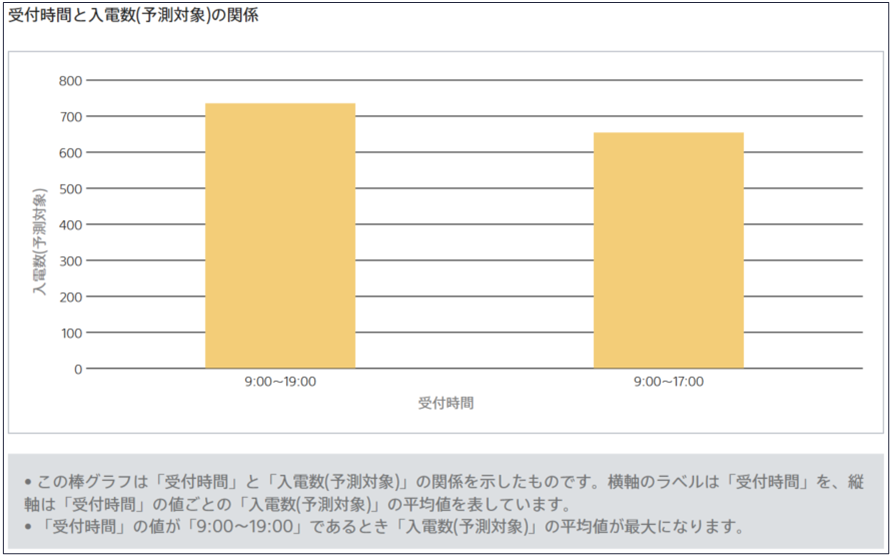
数値型x文字列型
片方が数値型でもう片方が文字列型の場合、文字列型の項目の値ごとの数値型の項目の平均値を棒グラフで描画します。
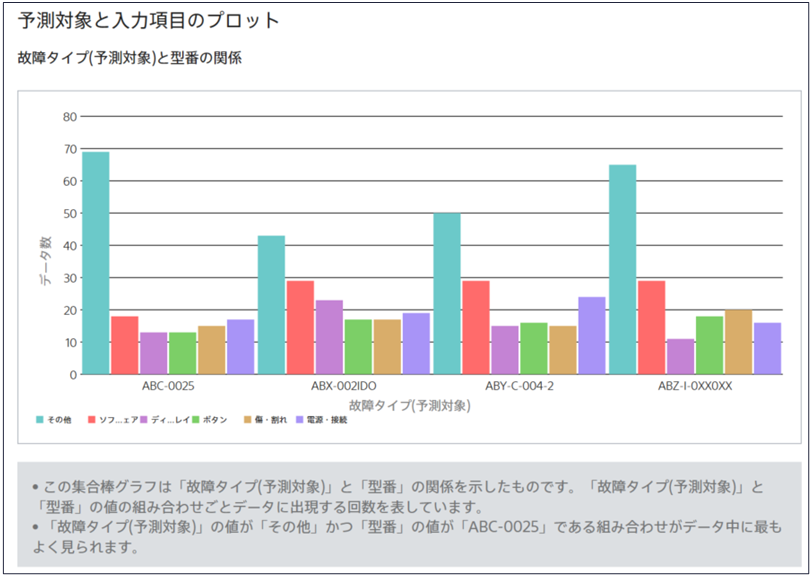
文字列型x文字列型
両方が文字列型の場合、集合棒グラフで値の組み合わせの分布を描画します。棒グラフの集合が片方の項目のある値を意味し、その中に含まれる色の異なるバーがそれぞれもう片方の項目の値を意味します。値の種類が多い場合は頻度の低いものが<その他>にまとめられます。