ソニーセミコンダクタマニュファクチャリング株式会社
- 業界
- 製造・販売
- 職種
- DX
- 予測テーマ
- 歩留予測
- 従業員規模
- 1,001名以上
- 事業内容
- 半導体の設計・開発・生産・カスタマーサービス
HOME > 導入事例 > ソニーセミコンダクタマニュファクチャリング株式会社


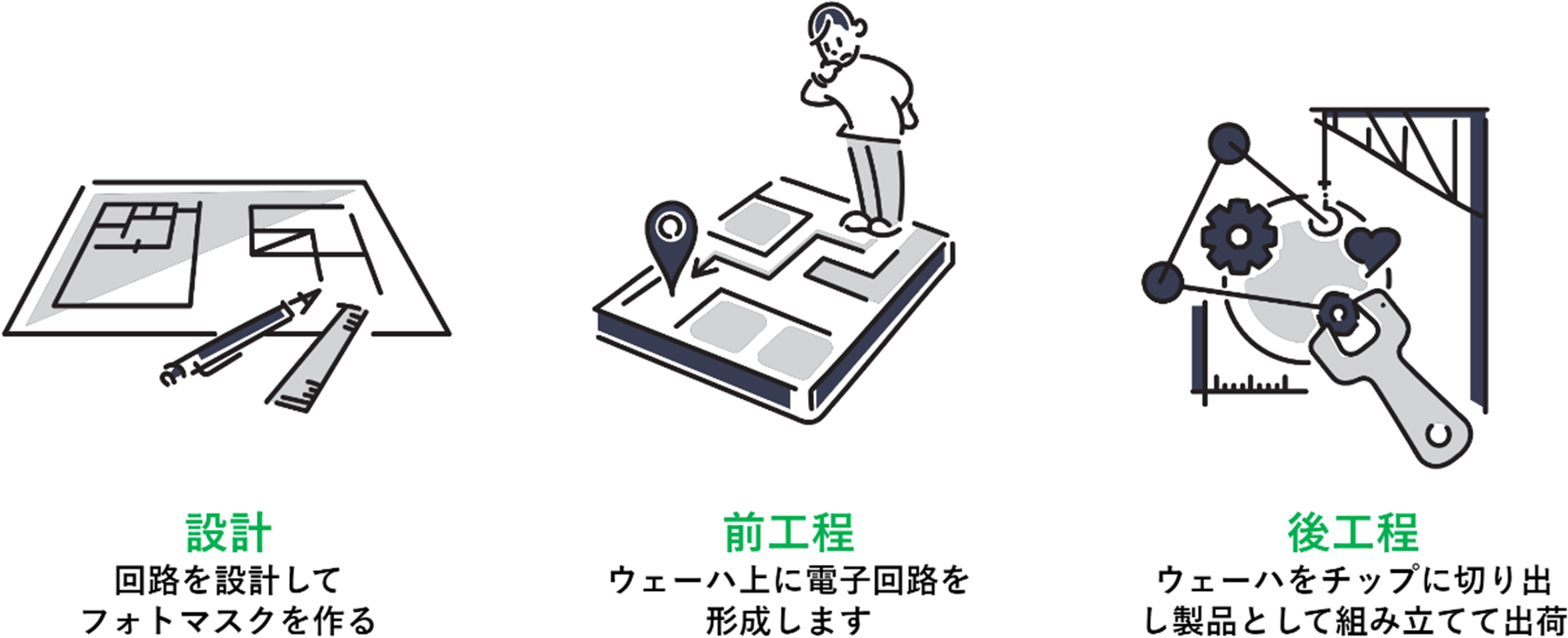
同社はイメージング&センシングテクノロジーを主軸として、先進技術を駆使したさまざまな半導体製品を製造、展開しています。
「前工程」でのPrediction Oneの活用に加えて、「後工程」と呼ばれるタイミングでのPrediction Oneの活用を行っています。「後工程」と呼ばれるタイミングでのPrediction One活用事例について、安田様、宮地様に話を伺いました。

安田様:私たちは会社全体で取り組んでいる「スマートファクトリープロジェクト」の中のAI応用研究会といったチームに所属しています。スマートファクトリープロジェクトはビックデータを活用し工場全体の最適化を目指す取り組みで、本チームでは様々なAI技術を半導体の製造ラインに導入するための技術開発と全社展開を担っています。
宮地様:半導体製造の後工程において、不良率予測を行いました。さらに予測結果を用いて歩留予測を行っています。半導体製造ラインでいう歩留とは以下を指します。
| 半導体の歩留 | ウェーハ(※1)1枚に設計されたチップの最大個数に対して生産された良品チップの数 |
|---|
一般的に後工程では、後述する予測モデル構築時の課題があり、ビッグデータの活用が進みにくい環境にありました。一方現場エンジニアからは、後工程の現場でも経験や勘に頼らない、ビックデータを用いた歩留改善活動や製造の最適化を目指していきたいという強いニーズがありました。
そこで歩留を予測し、事業計画の策定に必要な情報として活用するため、活動を始めました。
宮地様:予測モデル構築は、①モデル・データ検討②データ収集③データの前処理④予測モデル構築⑤評価分析の手順で行いました。各ステップでの課題は下記と認識し、課題解決に努めました。
| 予測モデルの構築ステップ | 課題 |
|---|---|
| モデル・データ検討 | 不良率のばらつき原因の研究 |
| データ収集 | 構造化データと非構造化データの混在(※2) |
| データの前処理 | 設備設定値の違いによるデータのばらつき |
| 予測モデル構築 | |
| 評価分析 |
モデル・データ検討ステップでは、製品ごとにパッケージサイズや構造が変わることで不良率が変動することがわかり、不良項目ごとにモデルを作りました。
またデータ収集のステップでは構造化データと非構造化データが混在しており、自動でデータを収集することが難しい状況にあったため、手作業でデータを収集しました。すべてを自動化するのではなく、難しい部分は人の手を介在させることでスムーズな運用を実現しました。
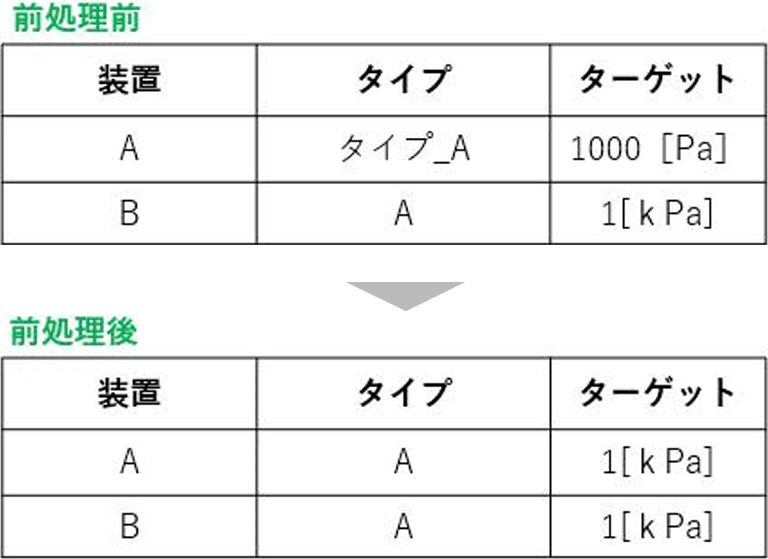
収集したデータの前処理をするステップでは、製品が作られる装置によって登録されている値が異なるため、データを一元的に扱えない状況となっていました。機械学習を行うためには機械学習用のデータが必要というわけです。この課題を解決するために前処理のルール化を行いました。いくつかのTIPSを下記にてご紹介させていただきます。
表記や単位、表現方法が異なるデータを抽出しルールを定めて、統一したデータ形式にそろえました。

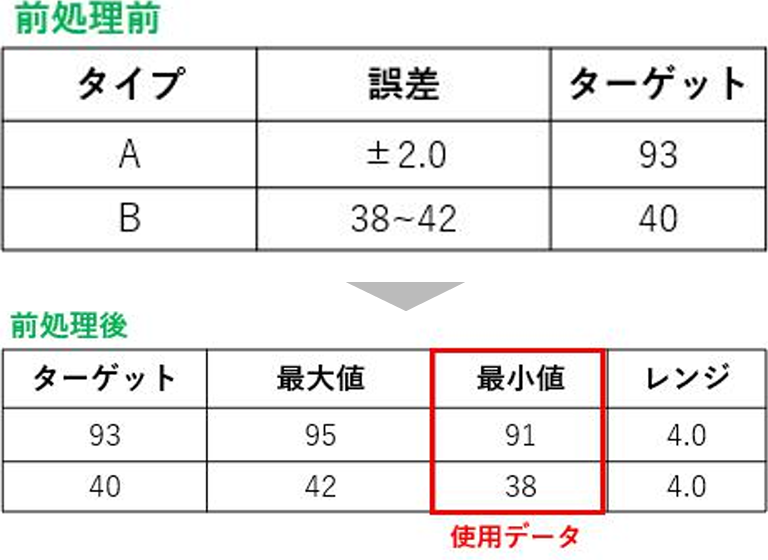
装置設定値のようなターゲットに対し、誤差許容範囲が定義されている変数については、最大値・最小値などの統計値を算出し、不良に最も影響する変数を導き出しました。変数を算出する際は「エンジニアが見ても納得がいく」、「Prediction Oneにデータを投入した際に特徴量を検知しやすく処理がしやすい」という点を特に注意しました。

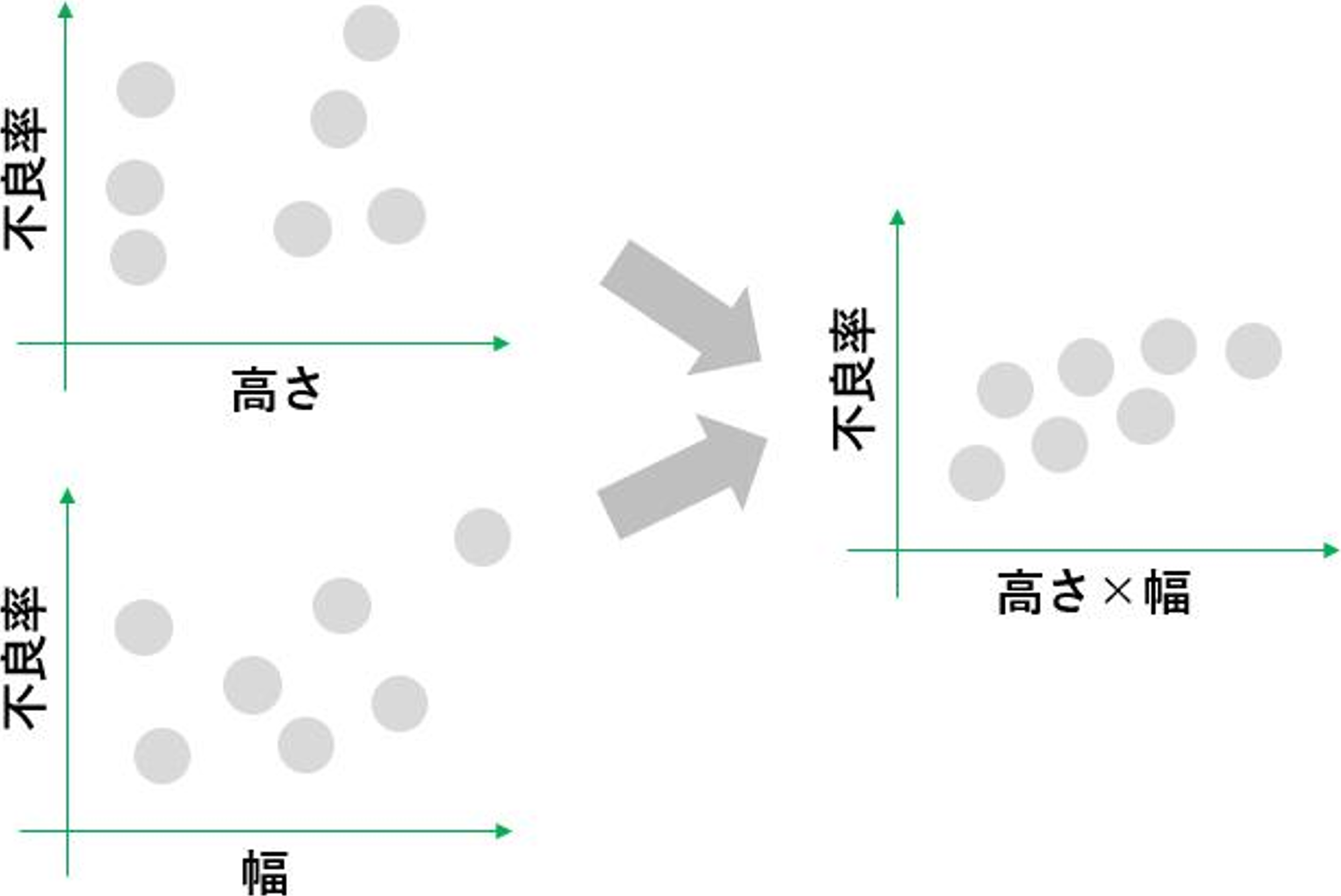
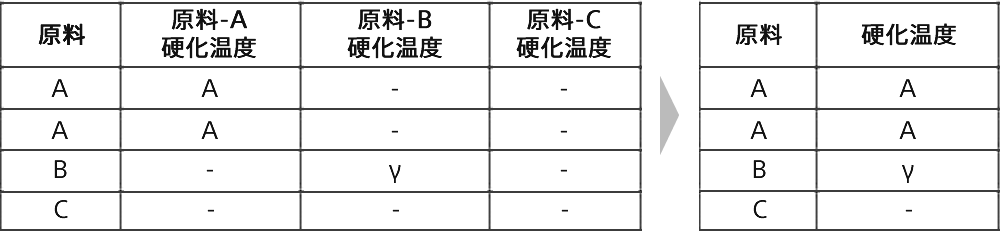
既に収集したデータの傾向を確認し、エンジニアの知見に合うように新たな説明変数を作成しました。例えば下図は高さと幅を組み合わせ、面積を説明変数に加えた例です。
処理フローによって列を分けて記入していたデータを1列にまとめ一元化しました。
次にこのような前処理を施したデータをPrediction Oneに投入しモデル作成を行いました。
Prediction Oneは数値データに加えテキストデータも扱うことができたり、空白のセルがある状態でも利用することできたりと、ある程度の前処理を行えばスムーズに予測に取り組むことができる点が非常に素晴らしいと感じています。
また機械学習に必要なモデリングやパラメータ―の設定を自動で行ってくれるため、難しい設定は必要なくデータを投入するだけでモデルの作成が行えました。

▲説明変数のイメージ
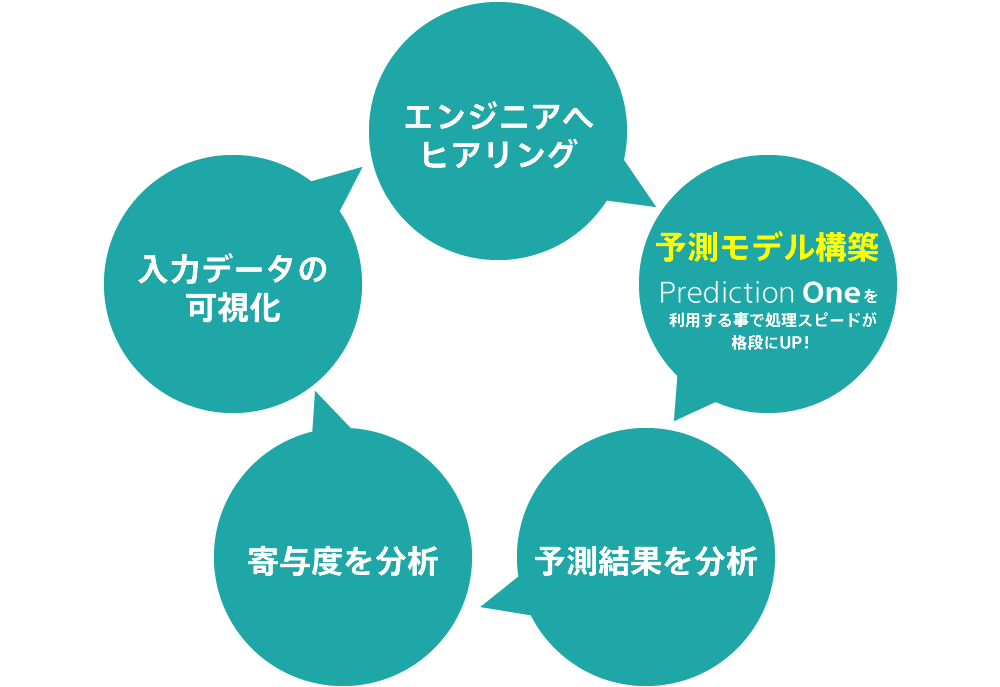
データの前処理の段階から現場エンジニアの意見を聞くように心がけていました。
エンジニアがこれまで積み上げてきたノウハウからかけ離れているデータセットではないか、鍵になるであろう説明変数について認識の相違はないかなど、細かくヒアリングを行いました。高い精度で、実態に即した形で予測分析を行うには、現場の意見は欠かせないと強く思いました。そのためには、「どんなデータを入れたからこの結果になった」と伝えられるよう入力データの可視化をし、データの説明と共に結果を伝えることを意識しました。モデルを改善していくには下記のようなサイクルを回していくが重要だと思っています。
宮地様:差異というよりも新たな発見が多かった印象です。
これまではワイヤーボンド(※3)について、エンジニアは「長さと本数」が歩留に影響すると考えていましたが、Prediction Oneの予測では「配置と本数が結果に影響すると算出されました。ダイボンド不良(※4)では、これまでエンジニアがイメージとして持っていた“パッケージのサイズ”と“反り”の相関について、Prediction Oneの結果より知見を裏付けることができました。今後の精度改善のためには直接要因である反り量が変数として必要になると考えることができました。
Prediction Oneの結果画面はどの変数がどのくらい結果に影響しているのかを表示してくれるため、エンジニアが見つけることのできなかった特性を発見でき、「ここを改善していけばいいのか!」とこれから取り組むべきヒントを得られる点が非常に魅力的だなと思いました。
ワイヤーボンドやダイボンド等の各項目で作成したモデルの予測結果を合算して算出しています。
これまで独自に作り上げたモデルの精度は【決定係数:0.19】ほどでしたが、Prediction Oneでは【決定係数:0.64】となり、大幅な精度改善が行えました。精度について現場のメンバーに確認したところ、「精度は十分である」とのコメントもいただき、実用化できるモデルができたことに非常に嬉しく思います。
最終的には予測結果を用いた、歩留改善など最適な生産ラインの構築ができればと考えています。そのためにもまずは、算出された結果から最適なパッケージ構造を作るためのヒントを得て、製造プロセスの中でどの部分にフォーカスして改善をしていくべきか決定し、実行していく予定です。
Prediction OneはAIモデル作成をするために必要なデータの前処理、加工、集約をノーコードで行うことができる「データ準備機能」をオプションとして提供しています。
プログラミングやExcelなどを利用したデータ加工に不慣れなユーザーでも、簡単にデータ準備を行える機能となっておりますので併せてご確認ください。
データ準備機能の詳細はこちら:https://predictionone.sony.biz/dl/dataprep.html


