敬愛大学
- 業界
- 教育
- 職種
- 教員
- 予測テーマ
- その他
- 従業員規模
- 1,001名以上

千葉市稲毛区にある敬愛大学は、建学の精神「敬天愛人」を教育の理念として、1966に開学しました。2024年3月に稲毛キャンパス整備の一環として新教育棟が完成し、敬愛大学と系列の敬愛短期大学の学生が共に学ぶ、活気のあるキャンパスが誕生しました。母体となる学校法人千葉敬愛学園は、2026年に創立100周年を迎えます。今回は、IR・広報室の工藤様・萩原様にお話をお伺いしました。
工藤様:本学のIR(Institutional Resarch)は、学内外の様々なデータを調査分析し、意思決定に資する提言等を行う部署です。簡単に言うと、教育や学生募集などの様々な活動におけるPDCAに貢献することです。広報では、ニュースの発信や媒体作りなどの仕事を行っています。私も萩原さんもAIについては、初学者からのスタートでした。
工藤様:最近、学園内でAIの活用やDXによる業務効率化が推奨され始めたので、ChatGPTやRPAなどを業務で使っている部署もあります。今のところ「できることから始めていこう」という感じです。
AI・データサイエンスの教育では、本学の副専攻「AI・データサイエンス」が、文部科学省が認定する「数理・データサイエンス・AI教育プログラム認定制度」のリテラシーレベルと応用基礎レベルに採択されました。両レベルの認定を千葉県で最初に受けた私立大学です。
このような背景があり、Prediction Oneを導入する雰囲気は醸成されていました。

工藤様:本学の広報の主な目的は、多くの高校生や保護者の方に本学を知ってもらい、興味を持ってくれる人を増やすことです。具体的には、オープンキャンパスへの参加や入学試験に志願してくれる人を増やすことです。そこでPrediction Oneを活用して、接触者データをもとに各個人が入学試験に志願する確率を予測する問題を考えました。また、萩原さんはオープンキャンパスの参加者の予測に取り組んでいます。
工藤様:Prediction Oneの導入前は、伝統的な回帰分析(※1)やベイズ統計モデリング(※2)を使って予測モデルを検討していました。プログラミングの技術や数理的な理解が必要であったり、プログラムのコードの書き方を本で調べたり検索したりするため、学習コストが大きいという課題がありました。
工藤様:導入の決め手は、操作の簡単さと計算の速さです。ある教員がPrediction Oneを教えてくれたことをきっかけにトライアル版を試したところ、以前の方法よりも格段に作業の効率が上がると感じたことが一番の理由です。製品版もぜひ使ってみたいと思いました。
これまでの方法では、大量の乱数生成を行っていたため、最終的な予測モデルの結果を見るのに時間がかかったり、夜通し処理を走らせても翌日に出勤するとエラーが出ていて絶望したりといったこともありました。
不要な変数を除いたコンパクトさを持ちながら、平均的に高い予測性能が得られるモデルを探索しています。変数を減らしてコンパクトさを上げると、予測性能が下がることがあります。逆に、変数を増やしすぎると新しいデータに対する予測がうまくいかないといったジレンマを抱えていました。最適なモデルを見つけるには試行錯誤が必要であり、作業の繰り返しには操作の簡単さや計算の速さが重要になります。比較検討したツールもありましたが、操作性やコスト面を考慮すると、Prediction Oneが最良と判断して導入に至りました。
工藤様:感覚的な推測ですが、従来と比べて何十時間以上は短縮できたのではと思います。これまでは自分で書いたコードでも数日が過ぎると、どのような処理を進めていたか詳細が分からなくなってしまうことがありました。いつ開いても同じ画面で、モデルの性能が表示されているPrediction Oneは、作業の継続性という点でも断然優れています。結果的に業務効率化にも繋がりました。
萩原様:別アカウントを利用しているメンバーとクラウドで簡単に情報共有ができる点もありがたいです。実際に業務で予測を行うとしたら作業の効率化は必須です。
工藤様:資料請求をした方やオープンキャンパスに参加していただいた方の情報は、データベースに記録しています。どのような経路や時期に接触があったのかを記録できるコーディング・ルールを作り、データを登録する仕組みを整えました。コーディング・ルールは、予測に寄与する変数をある程度考えた上で決めています。
登録されたデータは、定期的に目視による確認をして、不備を発見したら修正しています。不備に気づくことができるだけでなく、データの理解も深まります。毎年、しっかりとチェックしています。
萩原様:高校生の接触の頻度や時期、オープンキャンパスの参加回数、高校からの過去の志願者数などを含む約20項目を使っています。性別や住んでいる都道府県、高校の学区なども大切です。
萩原様:説明変数の中でもオープンキャンパスへの参加の寄与度が高いです。最後に接触した媒体名も重要です。高校生の大学進学の動向が大きく変わると、過去に集めたデータはバイアスになってしまう可能性があります。コロナ禍以降、進学に関する行動も大きく変化したと思うので、最近5年間のデータを使っています。
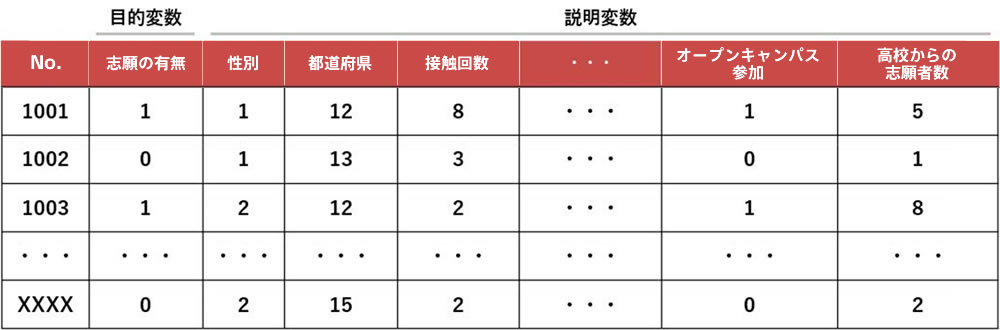
図 学習データのイメージ
志願は、入学試験の志願(あり=1, なし=0)を表す。IDを除くその他の項目を説明変数に利用した。
工藤様:モデルの総合的な判断には、AUCを使っています。自作のモデルではAUCが60%ほどでしたが、Prediction Oneでは85%前後になったので25ポイント近く改善したことになります。変数選択には、寄与度も参考にしています。画面に表示される星印の数は、モデルの性能が一目で分かり便利です。
ただし、オープンキャンパスの参加予測を行う二値分類では、予測確率をある閾値で1(参加)、0(不参加)に区切った場合、参加者数の期待値は160人だったのに対して、実際の参加者は80人でした。モデルは過大評価だったと言えます。参加予測の確率をいくつかの階級値に区切って層別に見ると、確率の高いグループでは実際の参加者は多く、低いグループでは参加者が少ないという結果になりました。大まかな参加傾向は、予測できたかもしれません。
萩原様:必要な説明変数については「これは使える、これは使えない」など試行錯誤を何度も繰り返して判断をしました。
工藤様:稀なイベントの発生は予測しにくいので、まずは、予測のしやすい問題を選んで取り組むことだと思います。データが正確に入力された整然としたデータベースを構築しておくことも重要と考えています。予測に役立つ変数を事前に検討して、データの収集方法を考えておく必要もあります。データに欠測値などの不備が多い場合は、それを埋める方法も考えなければいけないと思います。

志願やオープンキャンパスへの参加を予測するモデルでは、各個人に対して予測確率という形で具体的な値が出力されます。これを本学との関係性の強さを表す代理の指標と仮定すると興味深いと思います。一次元に縮約されているので、この値を次の施策に活用するのも容易そうです。
これは、Prediction Oneを使うことで、接触者の特徴を個人化できたと言い換えることもできそうです。関係性の強い人(予測確率の高い人)には、どのようなアプローチをすることでより志願に繋がりやすいか、反対に関係性の弱い人(予測確率の低い人)とは、どのようなコミュニケーションをとるべきかを考えていきたいです。施策の結果も確認する予定です。


