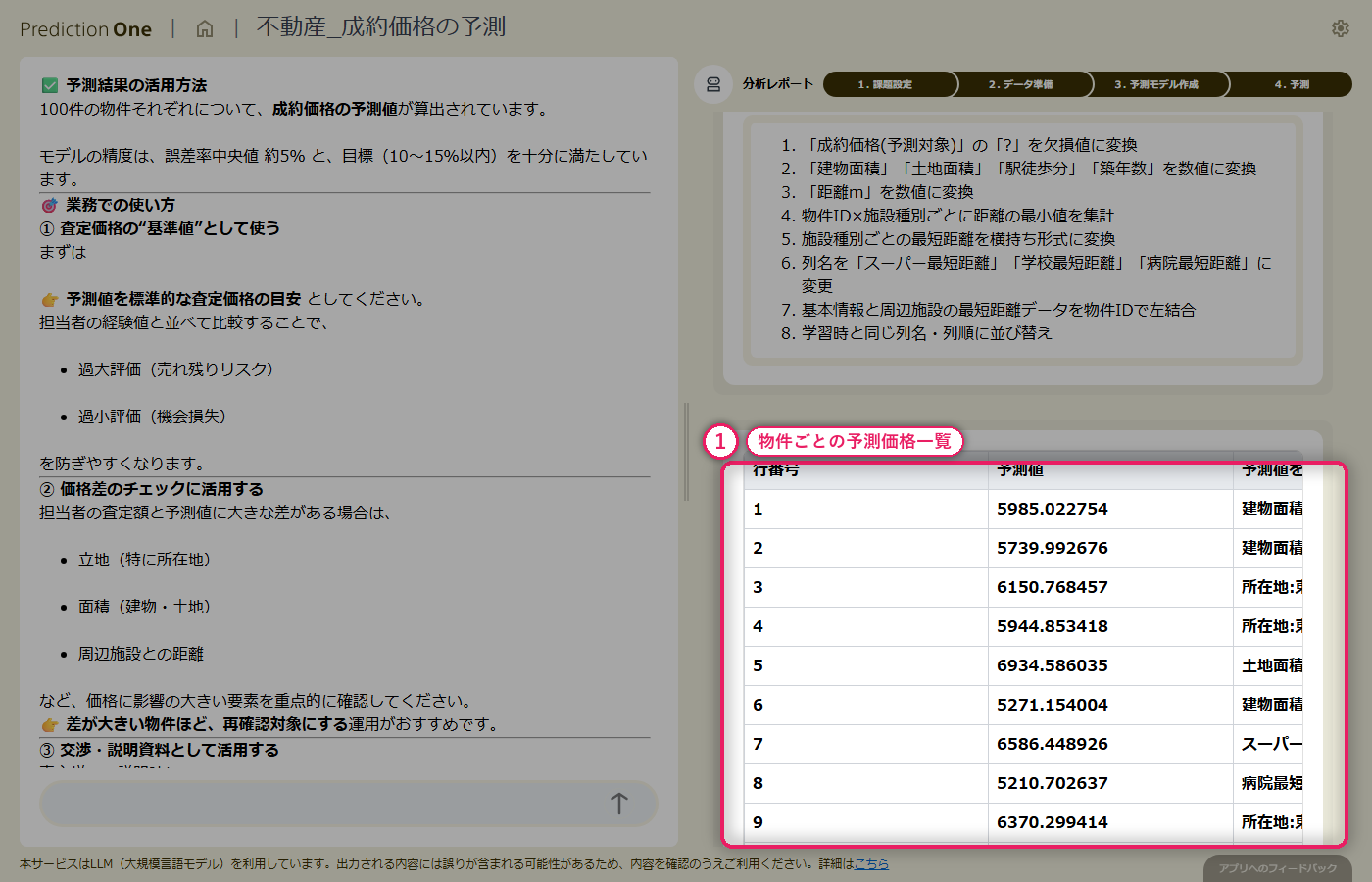
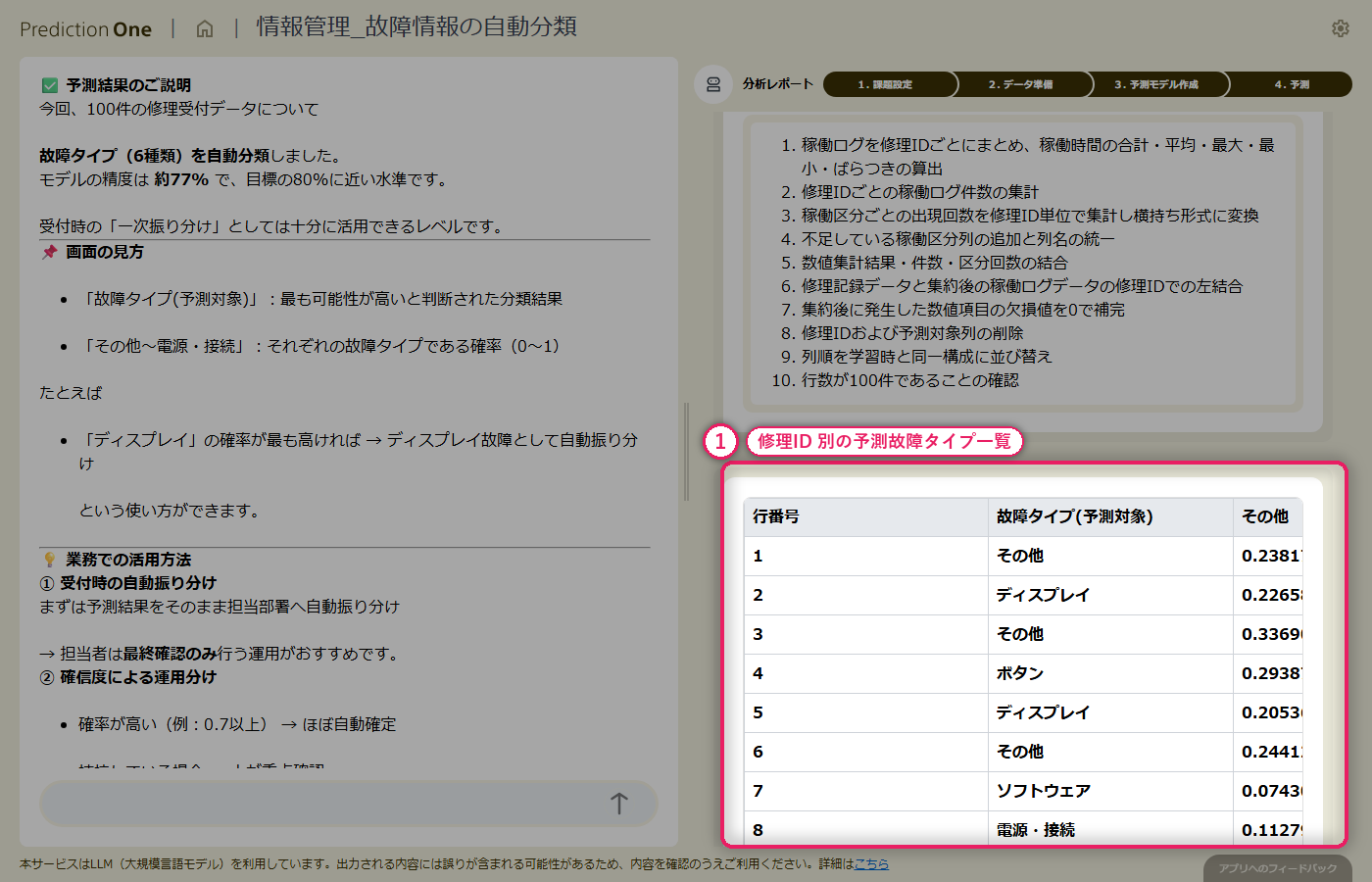
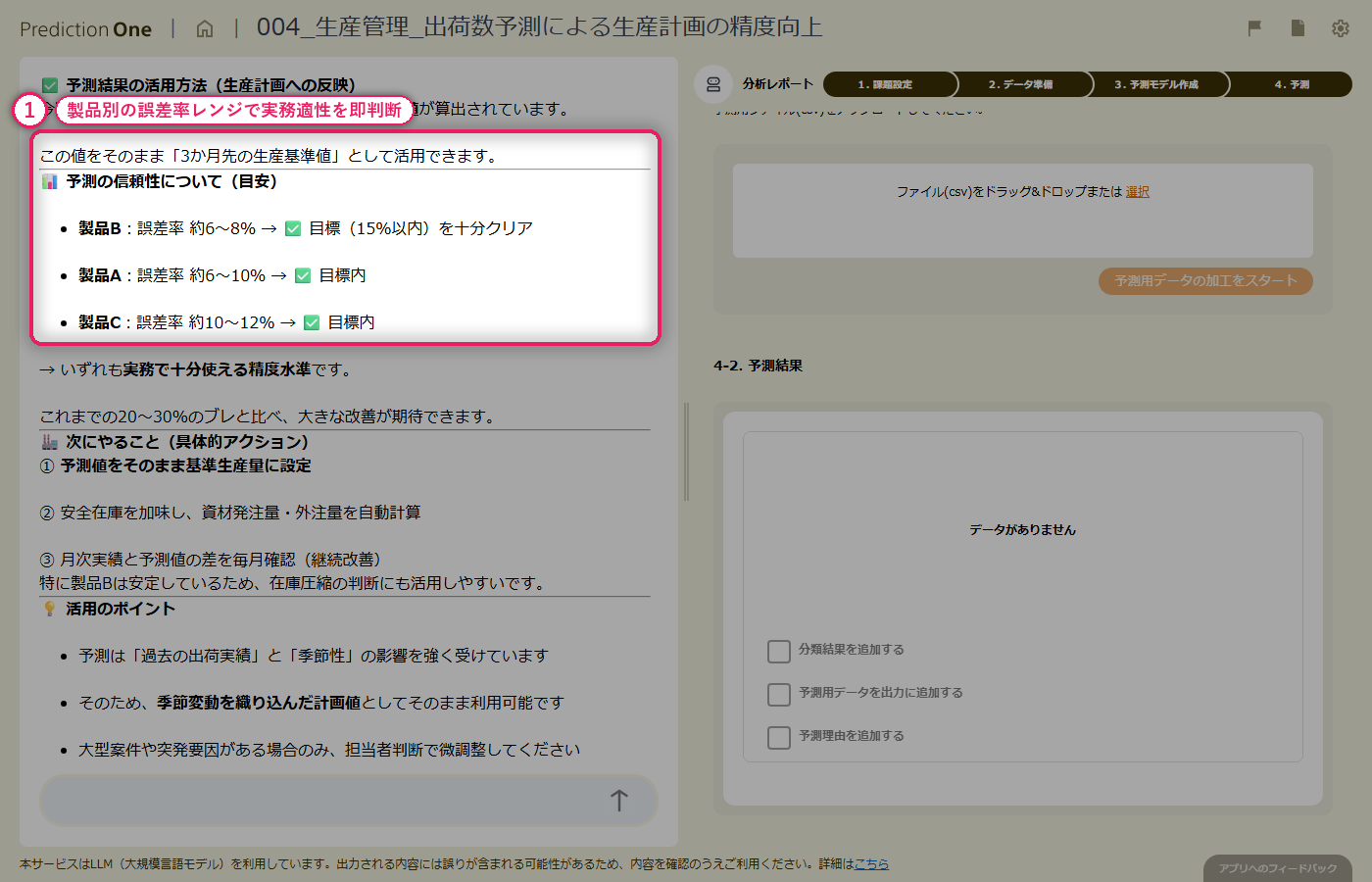
会員の属性と閲覧履歴から、プレミアムサービスの購入見込みをエージェントが予測。販促メール送付先を効率的に絞り込むための基礎となる予測モデルを、対話形式だけで構築します。
このチュートリアルでは、会員サービスを運営している事業者を想定し、「プレミアムサービスの購入見込みが高い会員は誰か」 を予測するモデルを Prediction One (エージェント版) で構築します。
会員の基本属性(顧客ランク・過去購入額・クーポン利用回数など)に加えて、サイトの閲覧履歴も学習データとして投入することで、属性情報だけでは見えない「購入意欲の気配」まで捉えます。複数のCSVファイルの結合・集計も、エージェントが自動で行うため、データ加工のコードを書く必要はありません。
最終的に、購入見込みが高い顧客を絞り込んで販促メールを送ることで、マーケティングコストを下げつつコンバージョンを上げる、という業務シナリオを体験できます。
背景:「全会員に販促メールを一斉送信しているが、反応が薄くコスト効率が悪い。誰に連絡するかを絞りたい」という課題を持つマーケティング担当者が、過去の会員データをもとに購入見込みスコアを算出することになりました。
基本属性だけでも一定の予測は可能ですが、サイト内でどんなページをよく見ているかという 行動データ を加えることで、属性だけでは見えない「実際の関心度」を捉えることができます。このチュートリアルでは、その「行動データの追加で精度がどれだけ上がるか」を、エージェント版の標準フローの中で確認していきます。
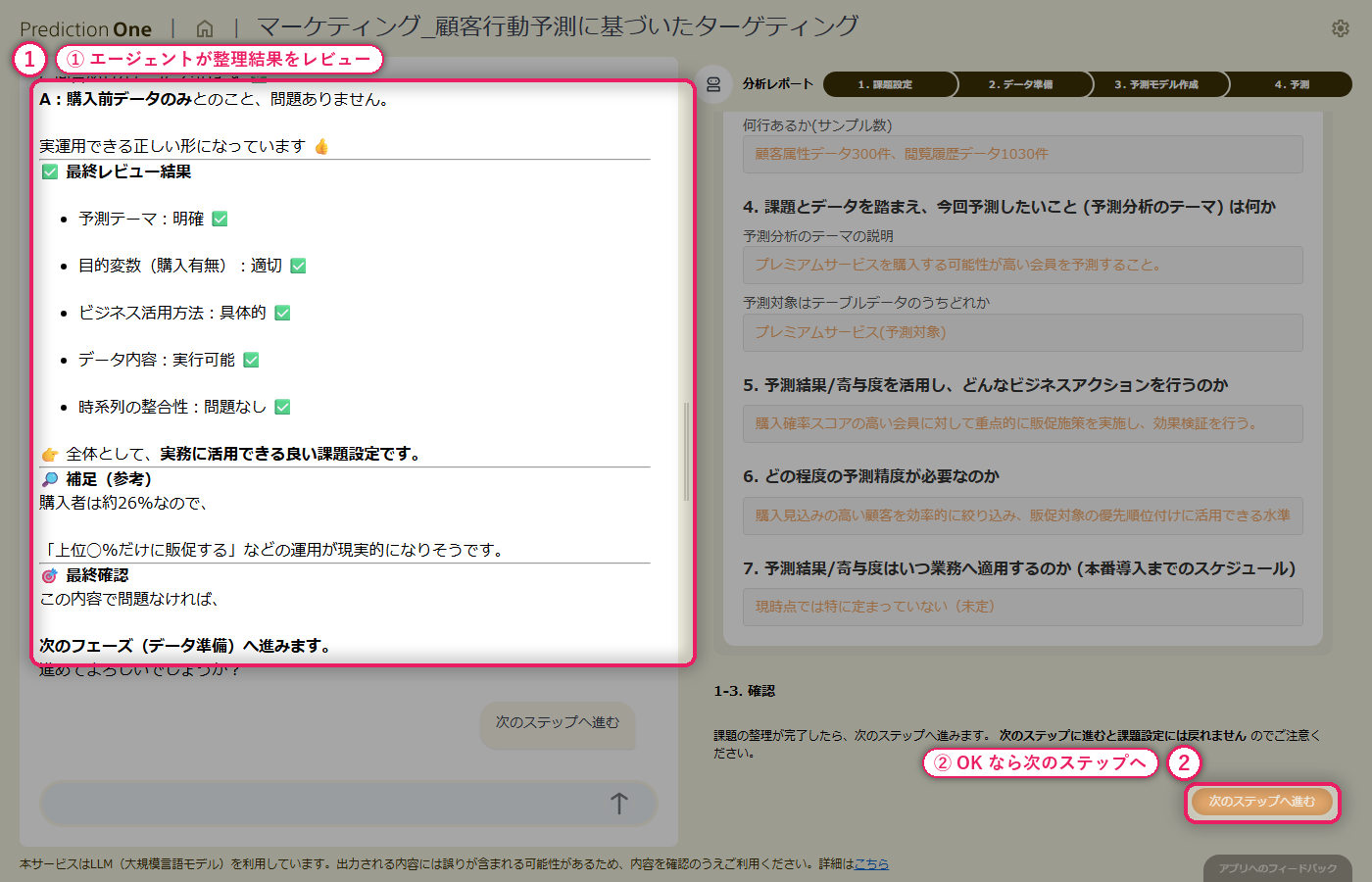
A0(プレミアムサービス購入の予測課題)と、顧客属性(A1)・閲覧履歴(A2)の学習用ファイルをまとめて投入します。エージェントはファイル構成を自動で読み取り、会員ID単位でプレミアム購入の有無を当てる二値分類タスクとして画面右側の課題シートに初期値を流し込みます。続くヒアリングでは、目的変数をプレミアム購入有無に固定すること、1顧客あたり複数レコードある閲覧履歴をどう扱うかといった論点を、対話形式で順に確認していきます。
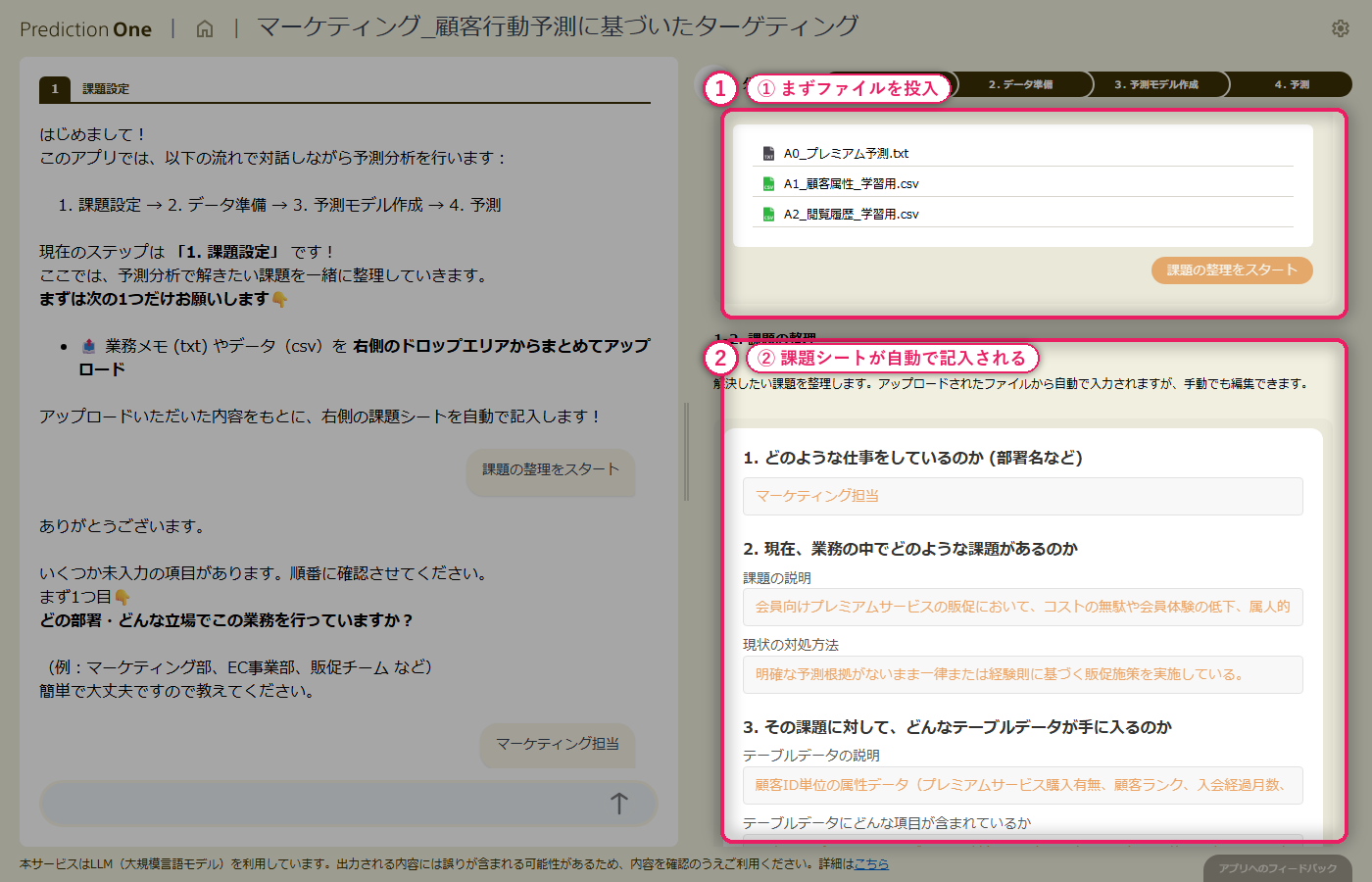
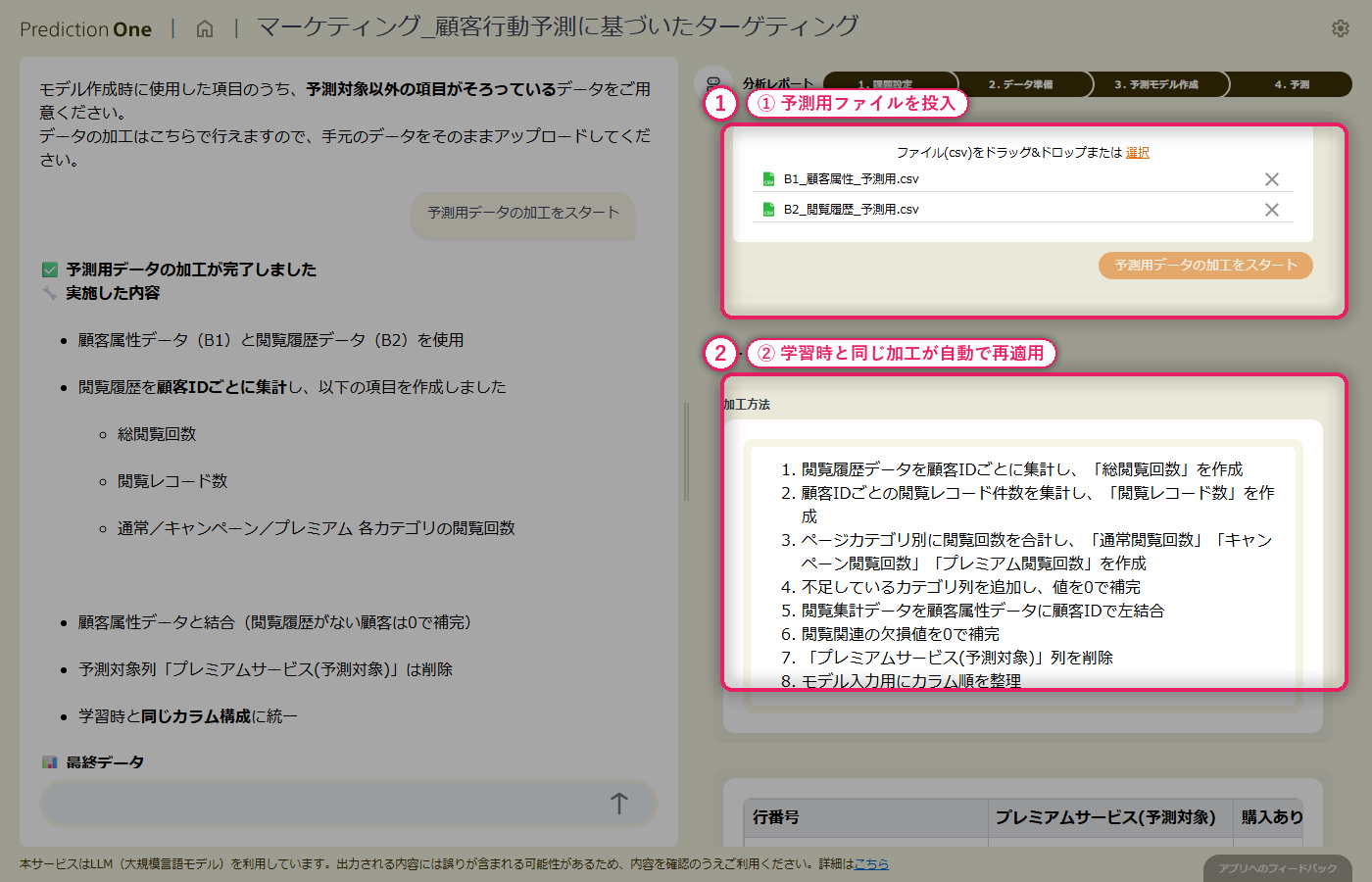
A0_プレミアム予測.txt と学習用の顧客属性・閲覧履歴を投入すると、エージェントが 2 つの CSV を「顧客ID で結合して二値分類する」タスクとして自動認識し、画面右側の課題シートに初期値を書き込みます。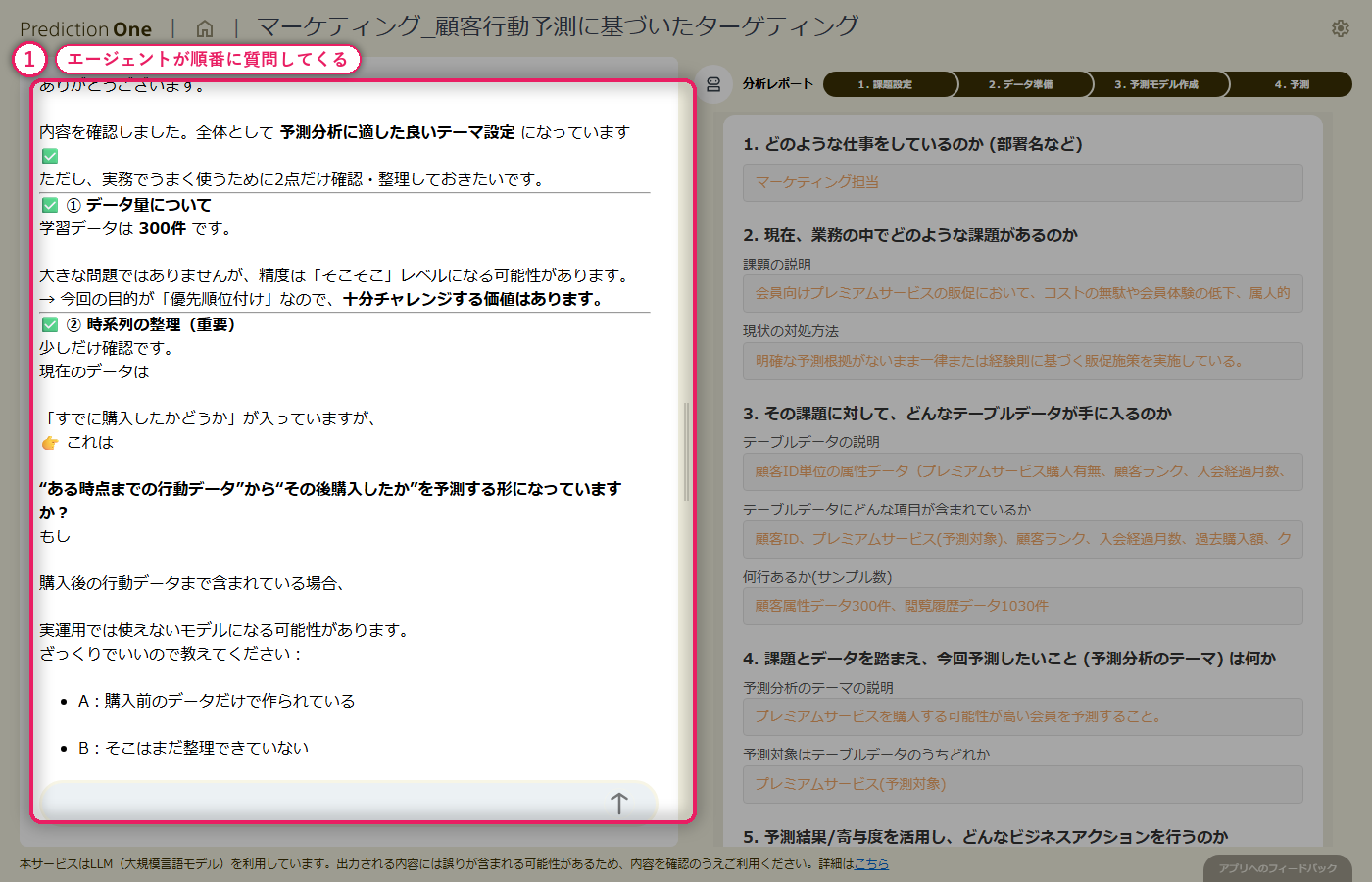
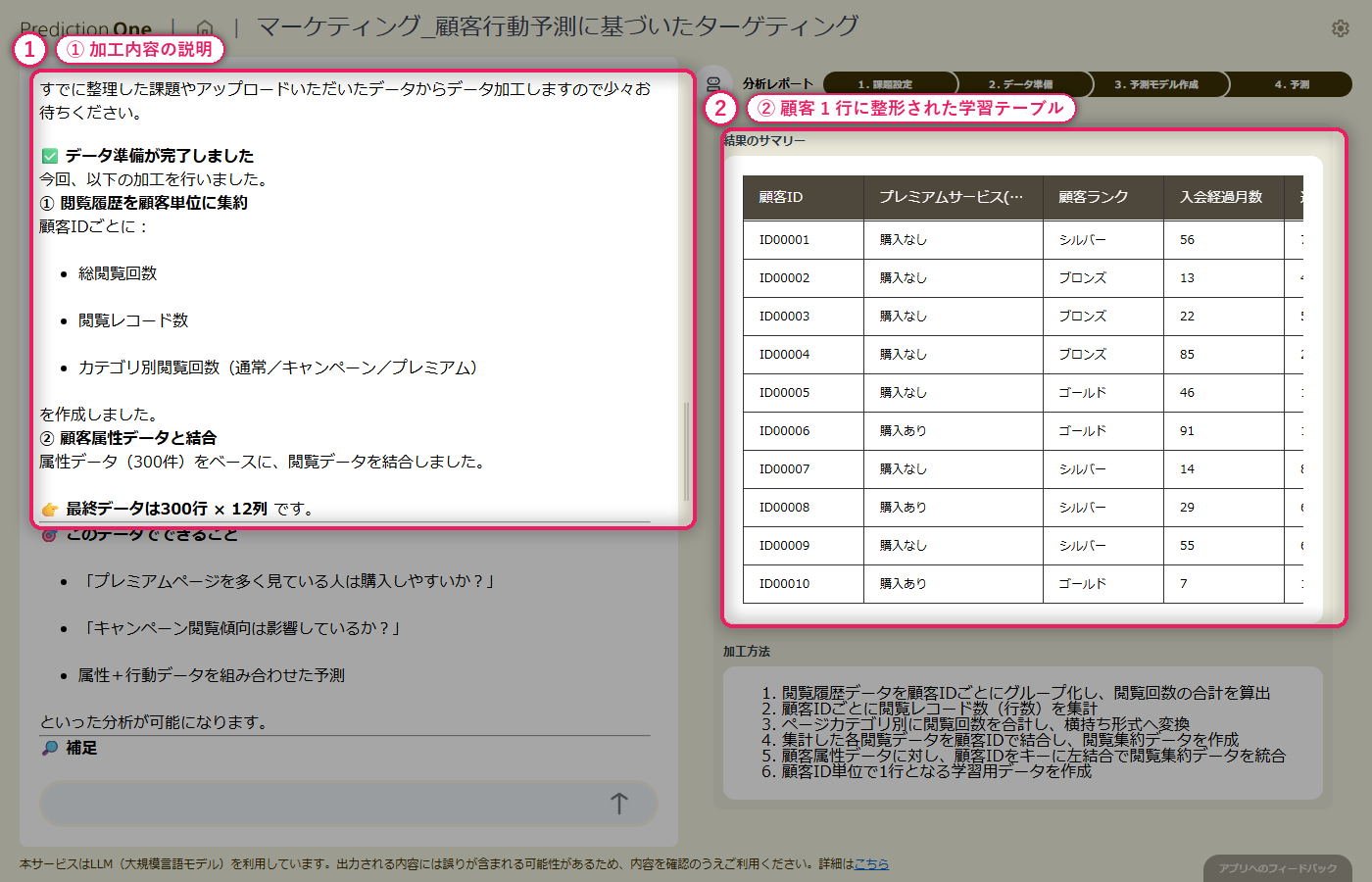
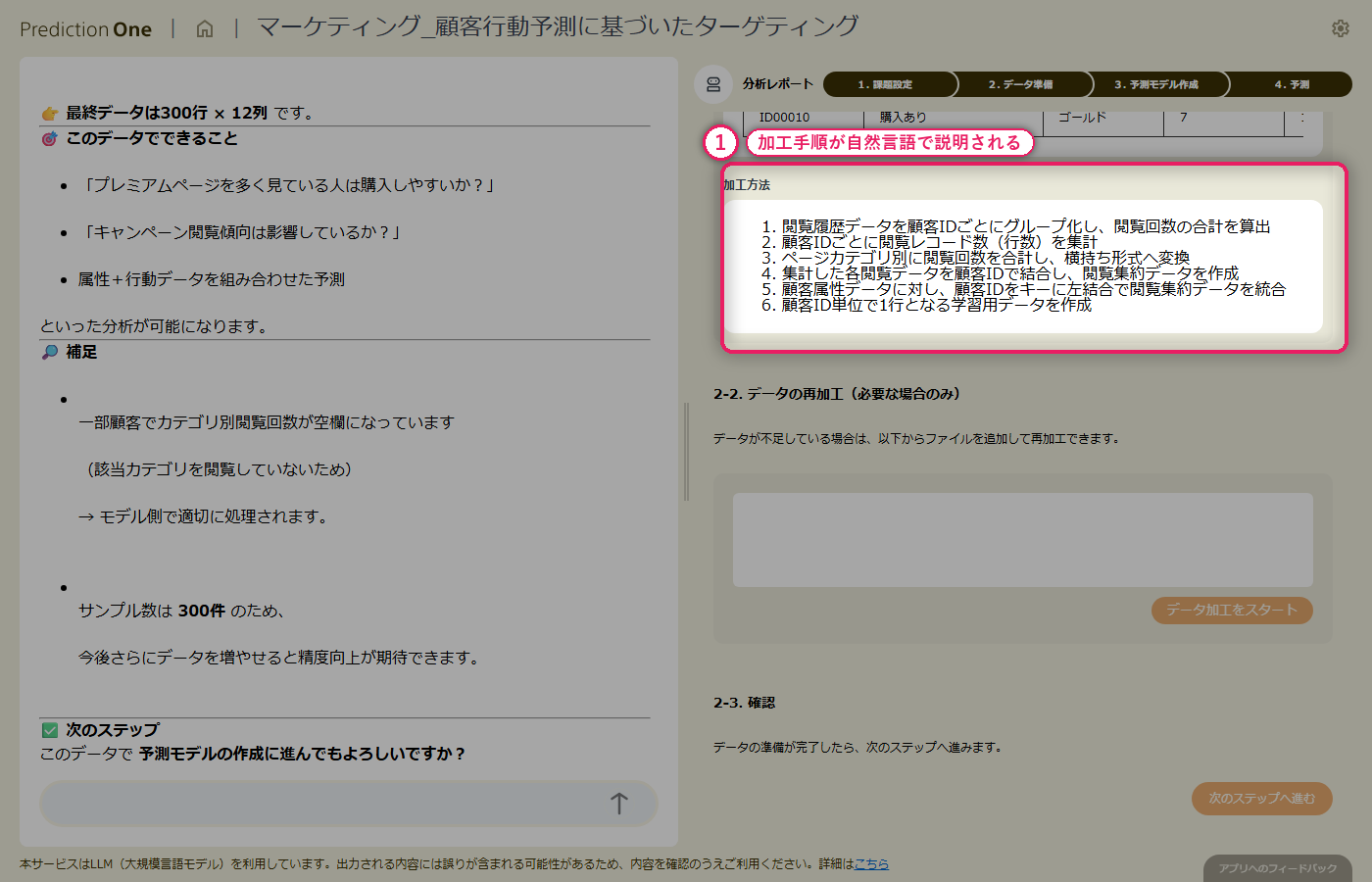
顧客属性(A1)の1顧客1行データに対して、閲覧履歴(A2)の複数行レコードをエージェントが自動で集計します。よく閲覧しているカテゴリの比率や閲覧回数などが顧客ごとの特徴量として展開され、属性単独では捉えづらい「サイト内でどんな関心を示しているか」がモデルに渡る形に整います。生成された学習用テーブルは、各処理がどのCSVのどの列に基づくかまでエージェントが自然言語で説明してくれるため、業務担当者でも加工内容をレビューできます。
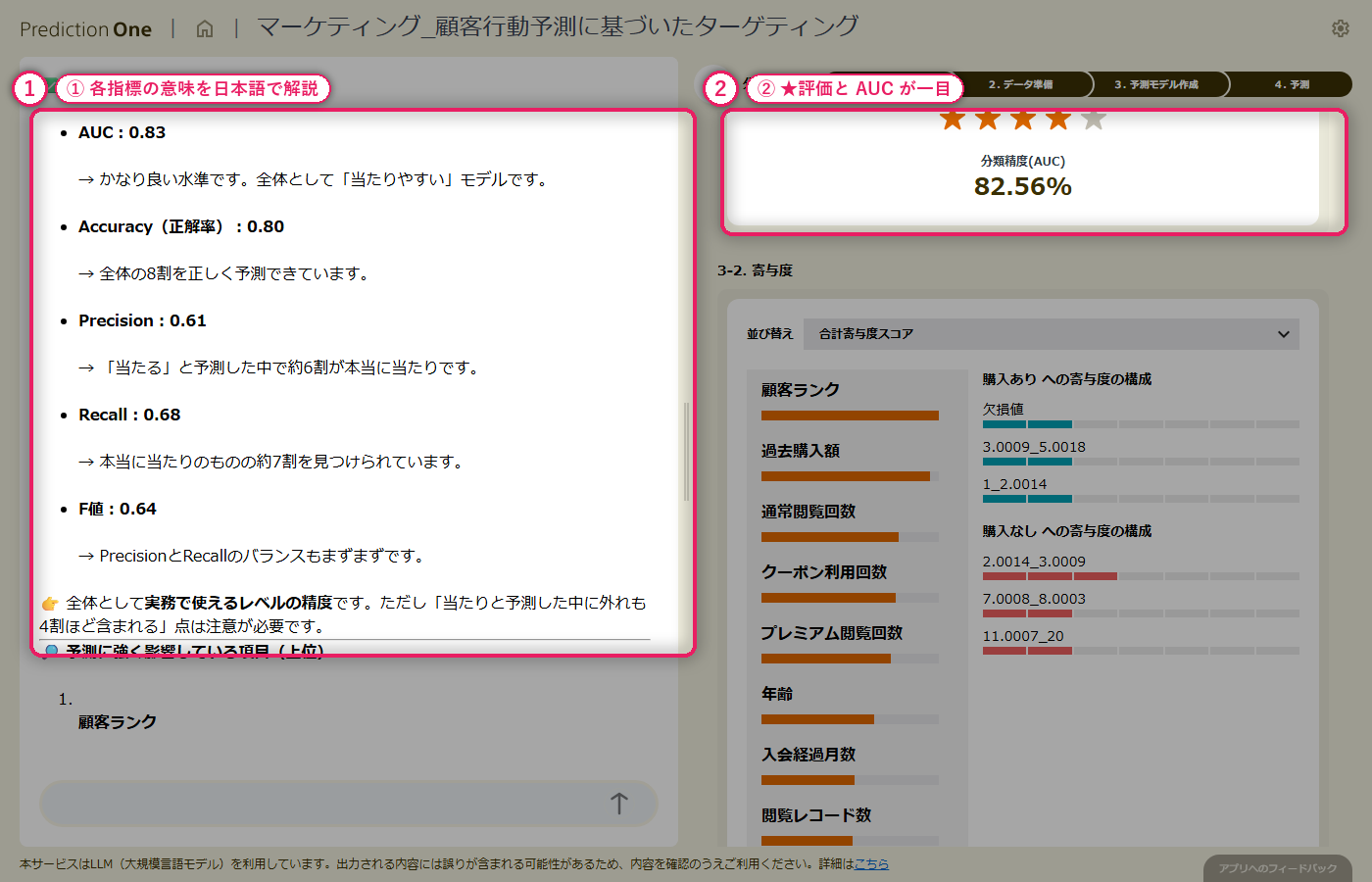
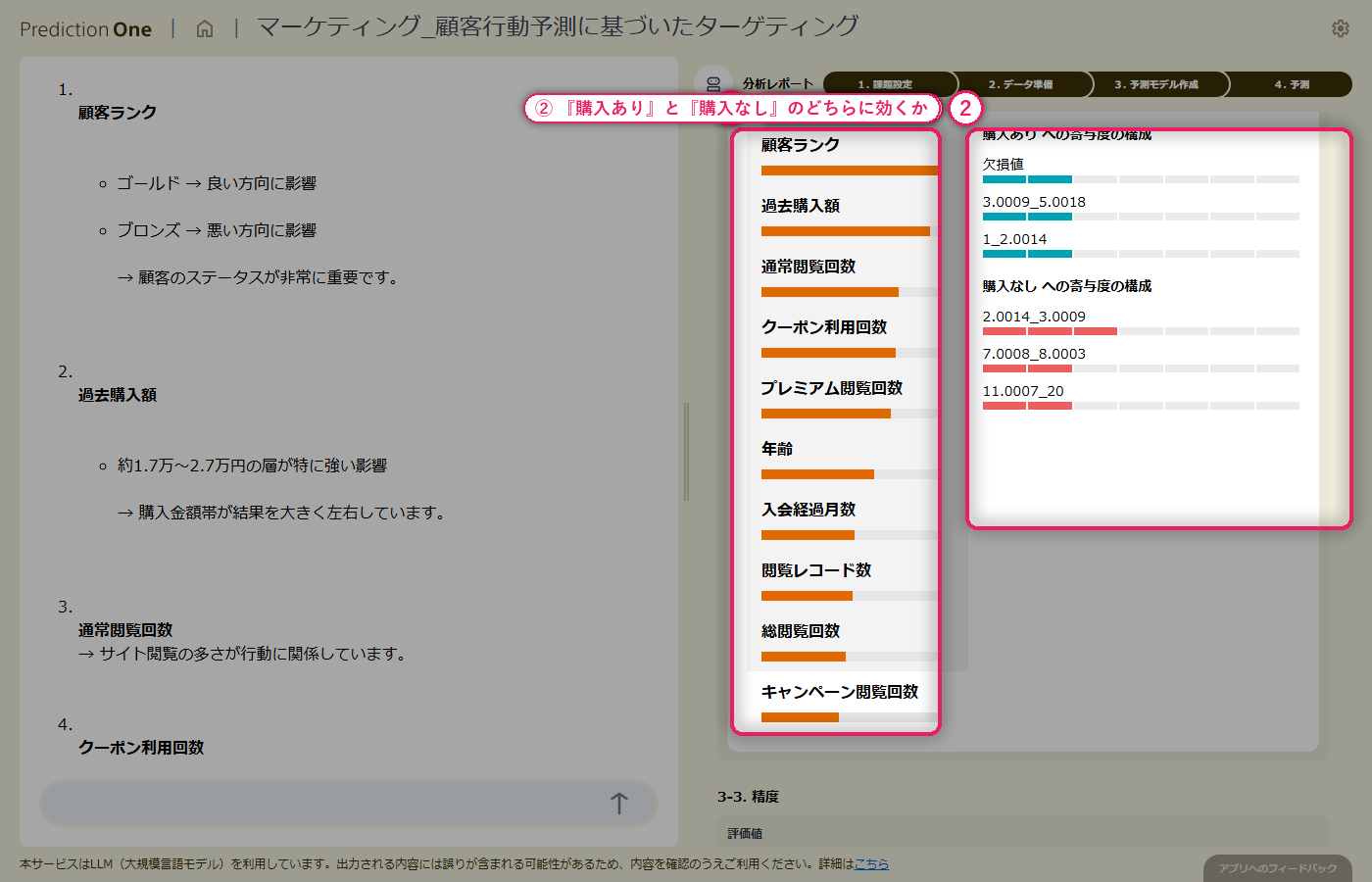
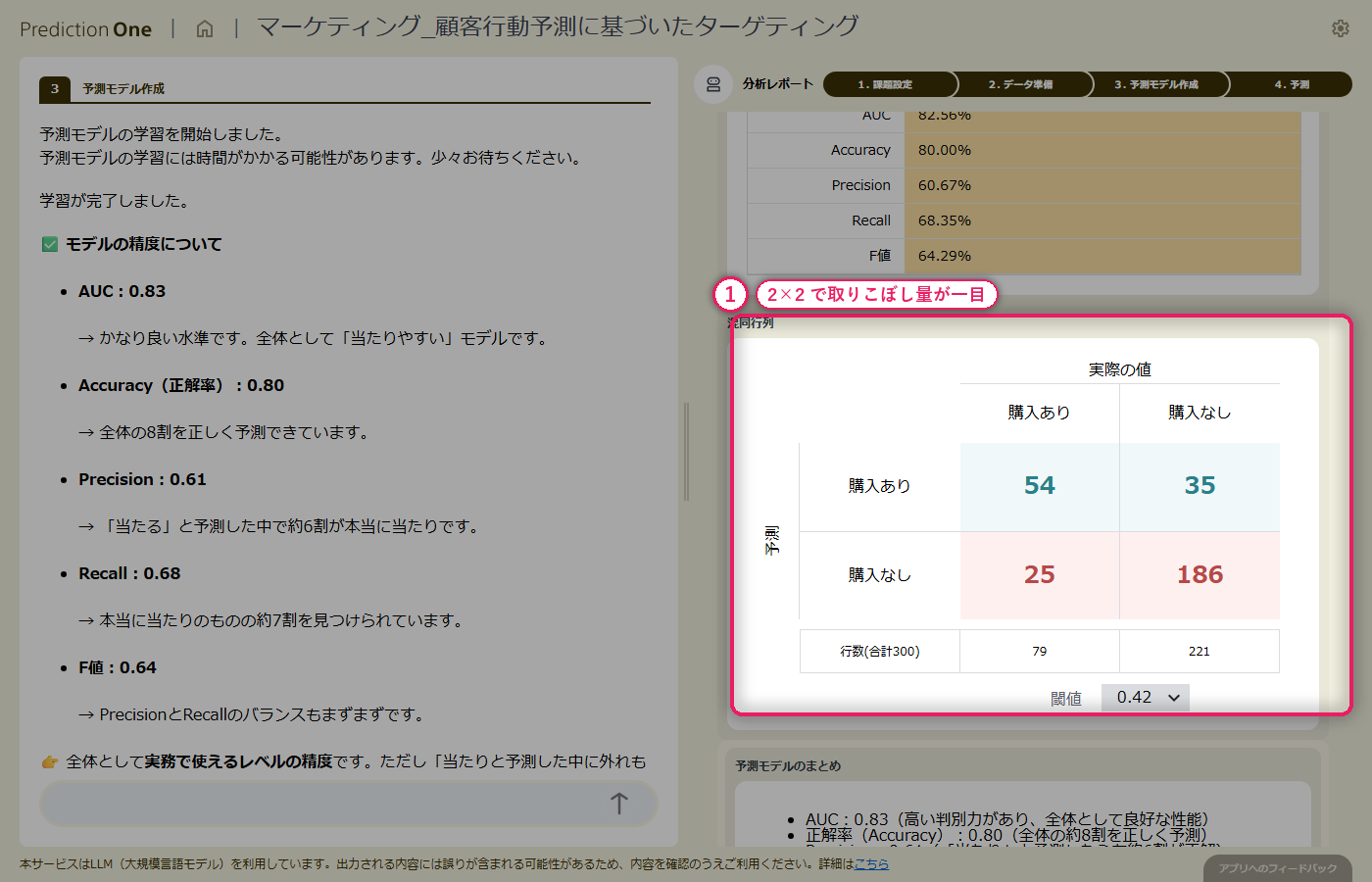
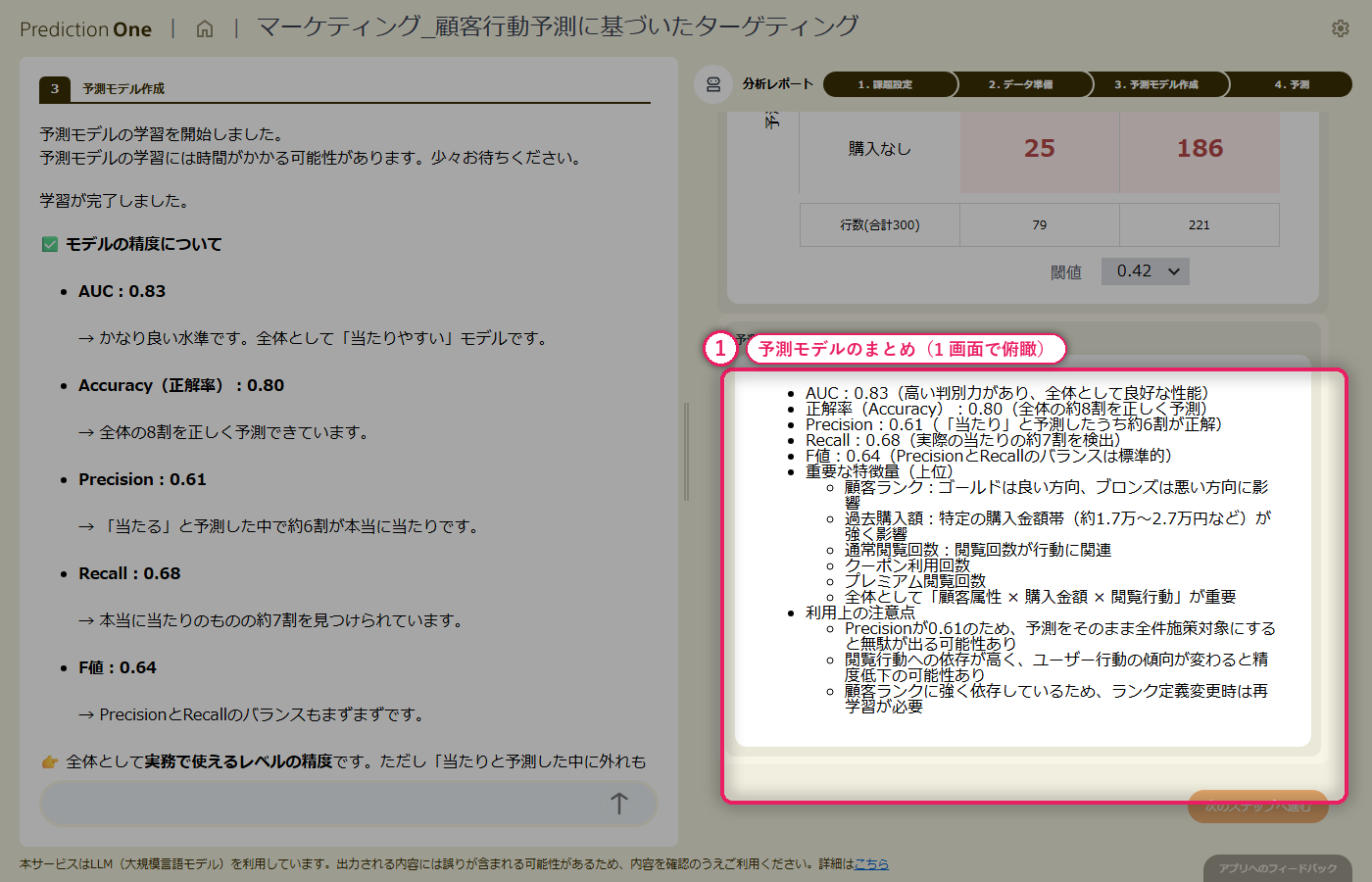
整えた学習用データから二値分類モデルを学習させると、分類精度(AUC)の水準評価が画面に出て、エージェントが「当たりやすいモデルかどうか」を日本語でコメントしてくれます。寄与度を見ると、顧客属性だけに頼っていた時には見えなかった閲覧履歴由来の項目が上位に入り、「関心の強さ」が実際のサイト内行動に現れている様子が読み取れます。予測精度・寄与度・混同行列・予測モデルのまとめ、とビューを切り替えながら、モデルの得意・不得意を多角的に検証できます。
Step 3 は 時間順ではなく、4 つの観点でモデルを確認します。
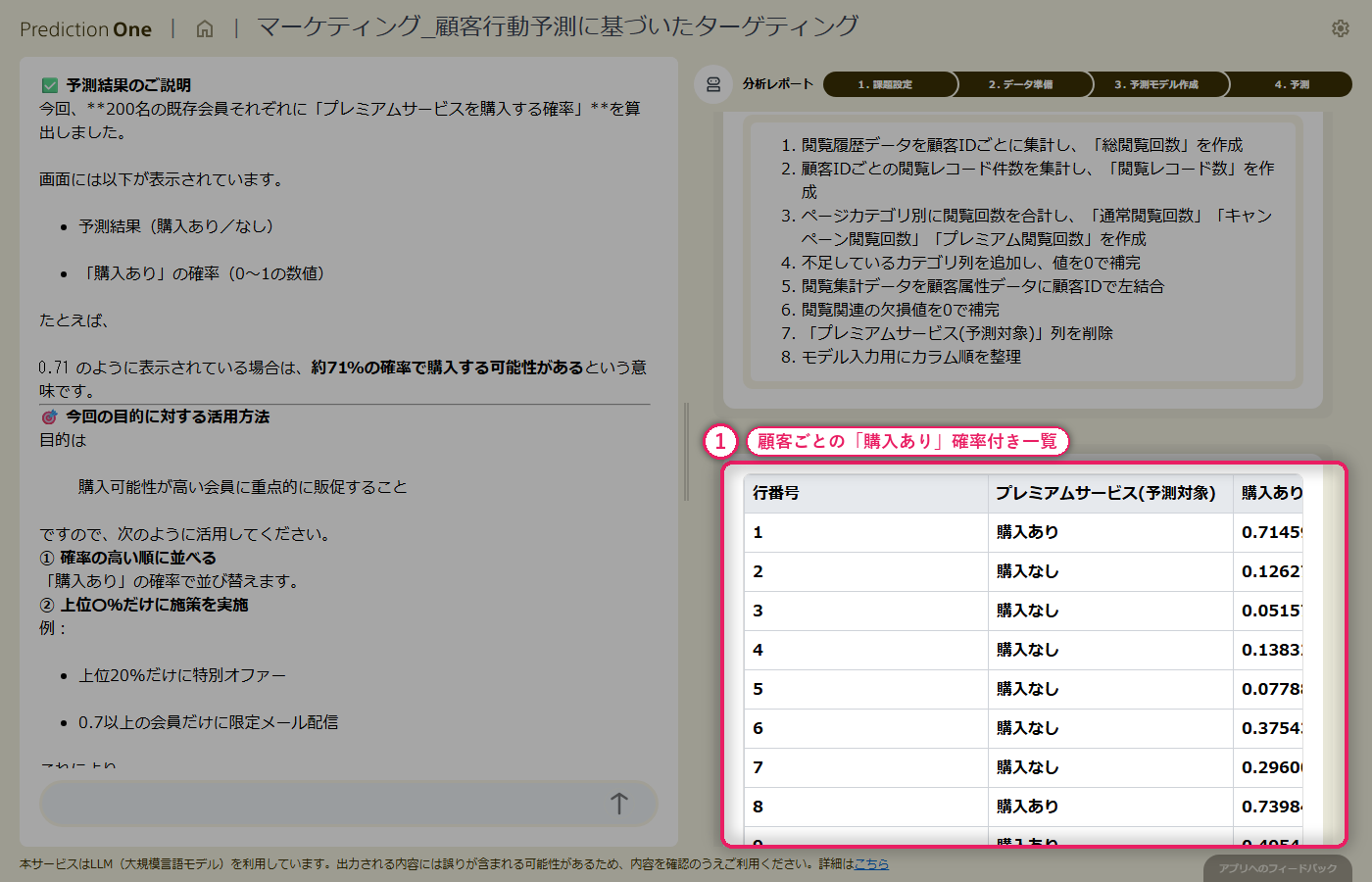
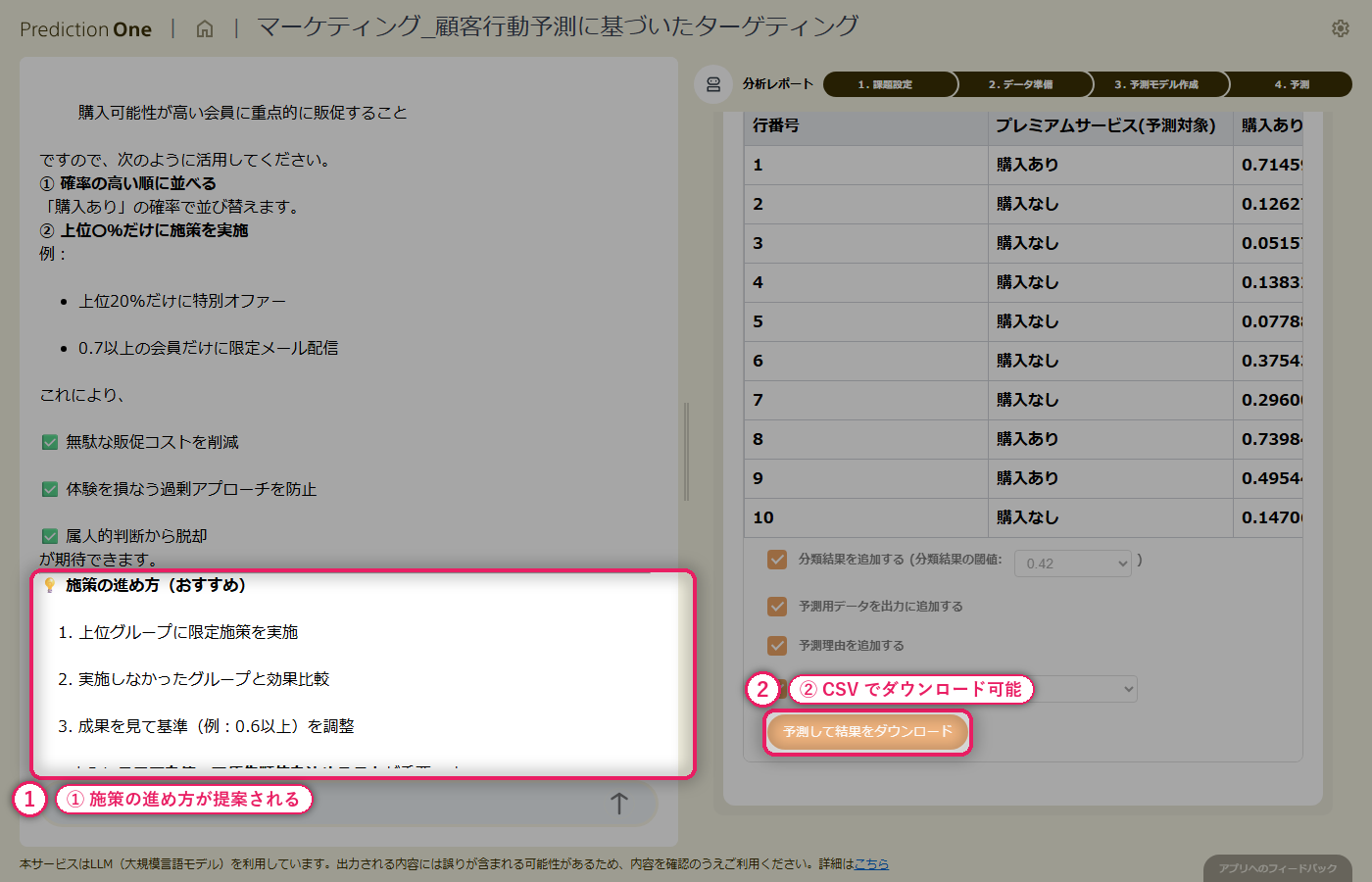
学習済みのモデルに、予測用の顧客属性(B1)と閲覧履歴(B2)をそのまま投入すると、会員ごとに「購入あり の確率」が付いた予測結果が得られます。この確率に閾値を設ければ、販促メールの送付対象を上位層に絞り込めます。エージェントからは「どの層を優先すべきか」「どんなクリエイティブが刺さりそうか」といった次アクションの提案も返ってくるので、運用開始直後から使える形になっています。
複数のCSVファイルにまたがる顧客属性と行動ログを、エージェントとの対話だけで結合・学習・予測できました。「誰に販促メールを送るべきか」を絞り込むためのスコアを、サンプルデータから得られています。
エージェントが出力する寄与度ランキングを見ると、閲覧履歴データ(A2)由来の特徴量が上位に入り、会員属性だけでは見えない「関心の強さ」を行動データが補完している様子が確認できます。