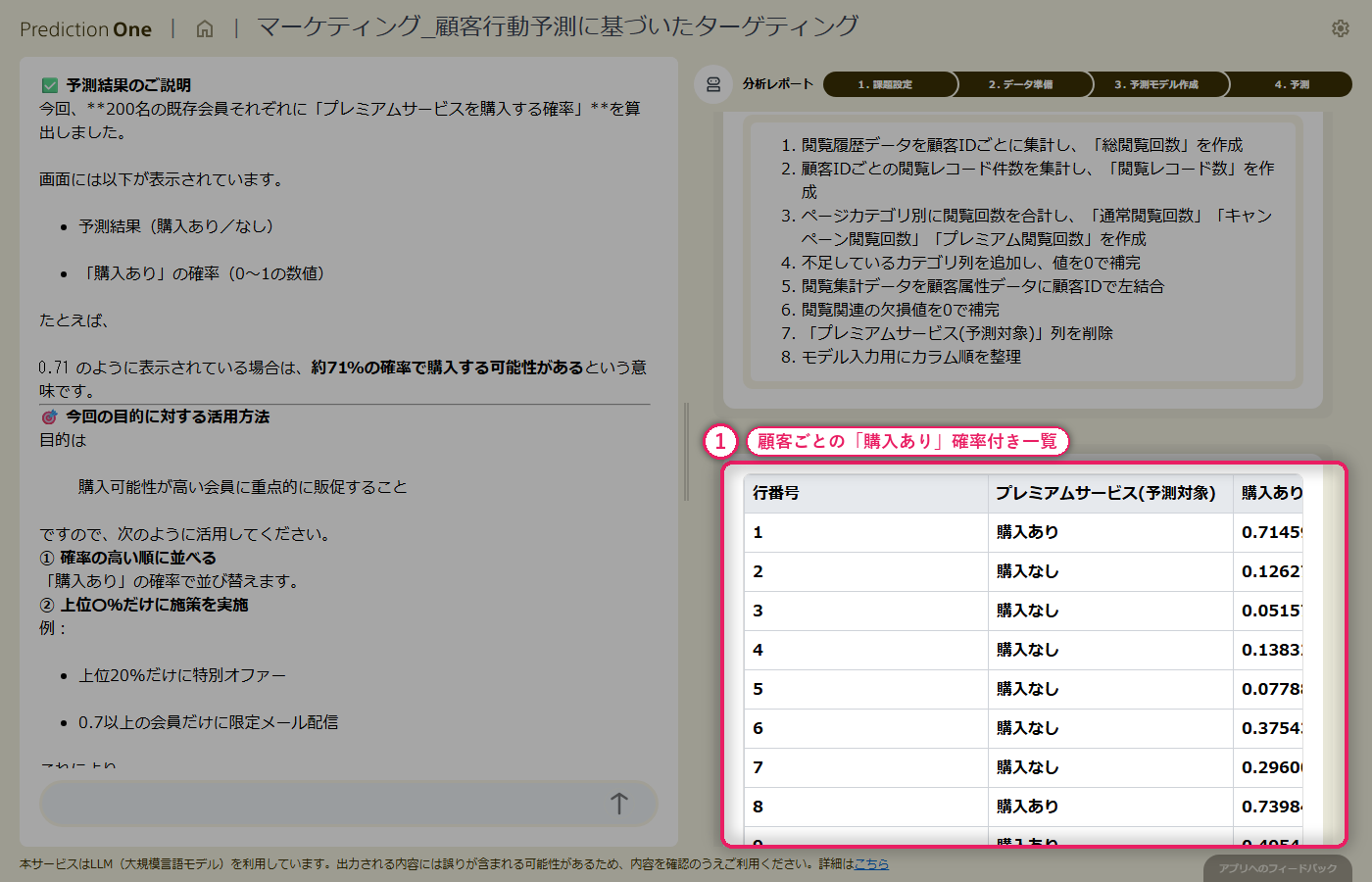
修理受付時に担当者が手作業で記録している「故障タイプ」を、指摘症状の文章と機器の稼働ログから6クラスに自動分類。テキスト列と複数行ログを組み合わせた多値分類モデルを、対話だけで構築します。
このチュートリアルでは、モニター製品の修理受付業務を想定し、「担当者が手作業で分類している故障タイプを、エージェントと一緒に自動判定する」多値分類モデルを Prediction One (エージェント版) で構築します。
指摘症状の自由記述(テキスト)に加えて、機器の稼働ログ(月次の稼働時間と稼働区分)というサブデータを組み合わせて学習します。テキスト列と複数行の時系列ログをまとめて扱うケースとして、エージェント版の強みが分かりやすく体感できる題材です。
最終的には、テキストだけで学習する場合と稼働ログを追加する場合の精度を比較し、「どんなデータを足すと予測が改善するか」をデータから読み解くインサイトも得られます。
背景:「モニター製品の修理受付では、担当者が指摘症状を読んで故障タイプを分類しているが、件数の増加と担当者ごとの判断のばらつきが課題になっている」というシナリオです。故障タイプは「ソフトウェア / 電源・接続 / ディスプレイ / 傷・割れ / ボタン / その他」の6種類で、これを自動判定する分類モデルを構築します。
特徴的なのは、予測対象に効くシグナルが「指摘症状の自由記述(テキスト)」と「機器の稼働ログ(数値 × カテゴリ)」の両方に散らばっている点です。テキストだけでもある程度分類できますが、症状が曖昧なケースでは誤分類が発生します。そこで稼働ログを加えることで、「ソフトウェア故障の機器は修理前に高負荷稼働が多い」といったパターンを捉えられるかを確認します。
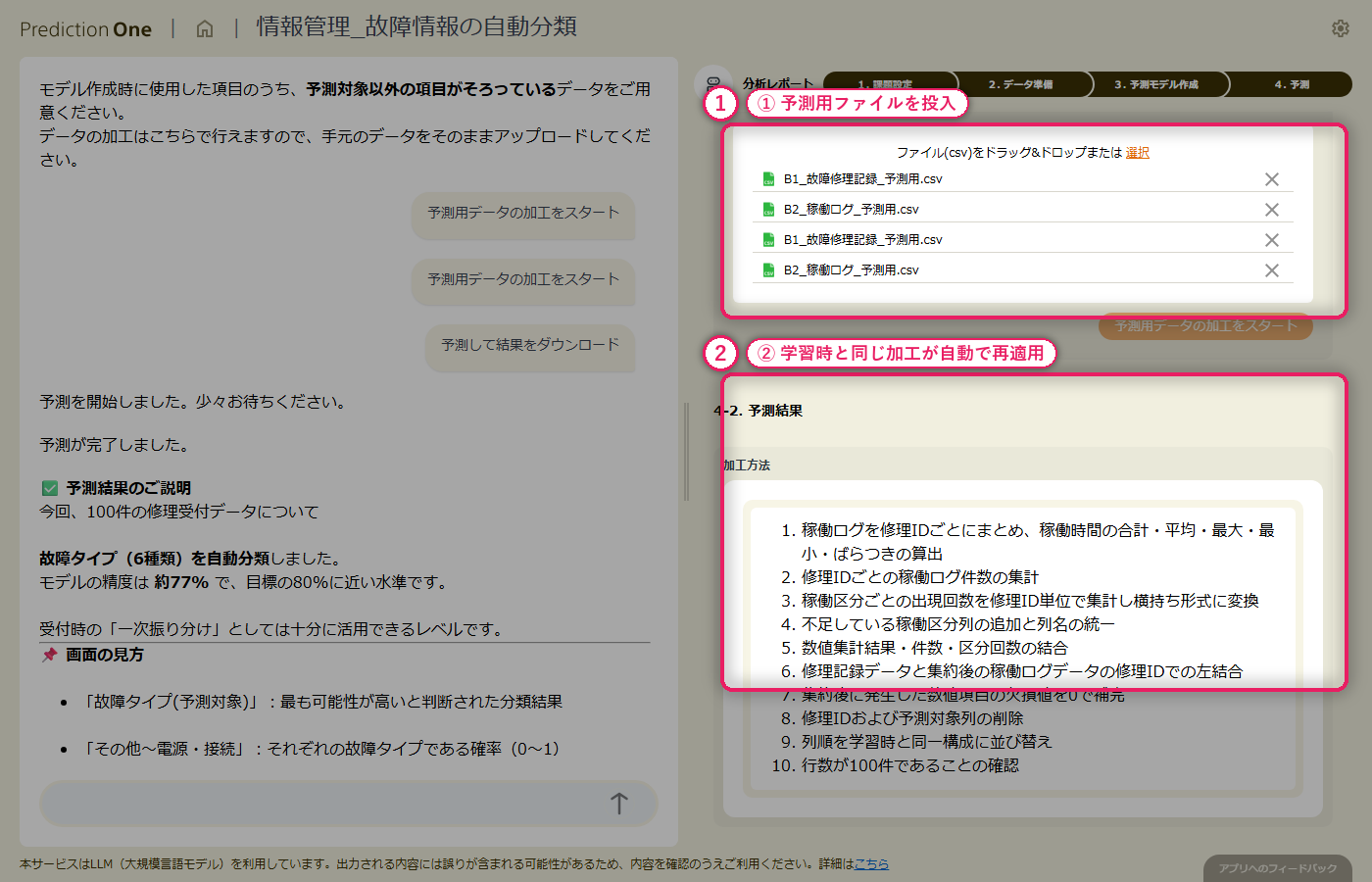
A0(6クラス故障分類の業務説明)と、修理記録(A1)・稼働ログ(A2)の学習用ファイルを投入します。エージェントは自由記述の指摘症状と1機器複数行の月次稼働ログを自動認識し、修理ID単位で故障タイプを当てる多値分類タスクとして課題シートを組み立てます。ヒアリングでは、テキスト列を学習対象に含めるかの確認や、稼働ログを何ヶ月分さかのぼって使うかといった論点が対話で整理されていきます。
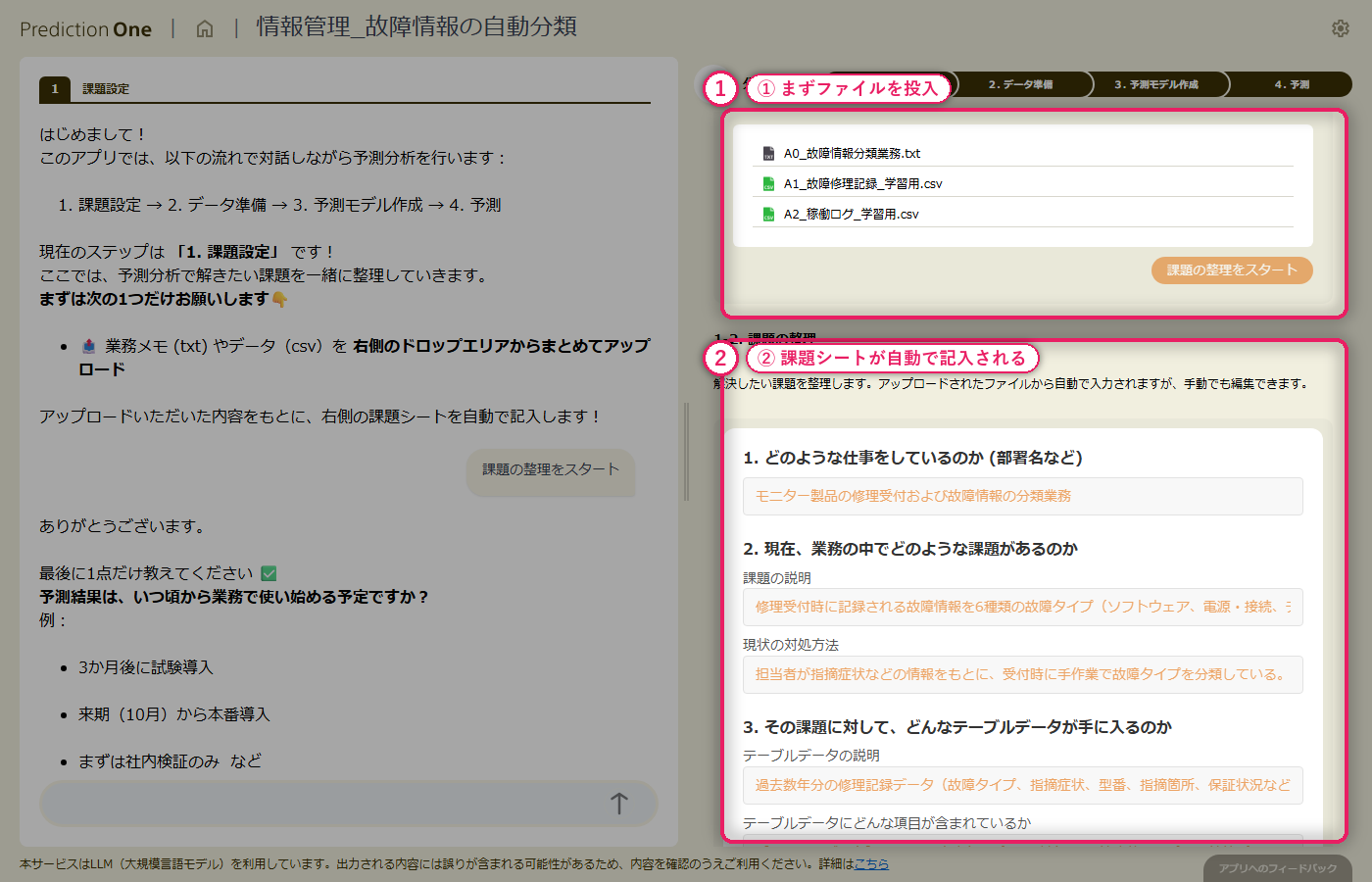
A0_故障情報分類業務.txt と学習用の修理記録・稼働ログを投入すると、エージェントが「修理ID で結合して故障タイプを多値分類する」タスクとして自動認識し、課題シートに初期値を書き込みます。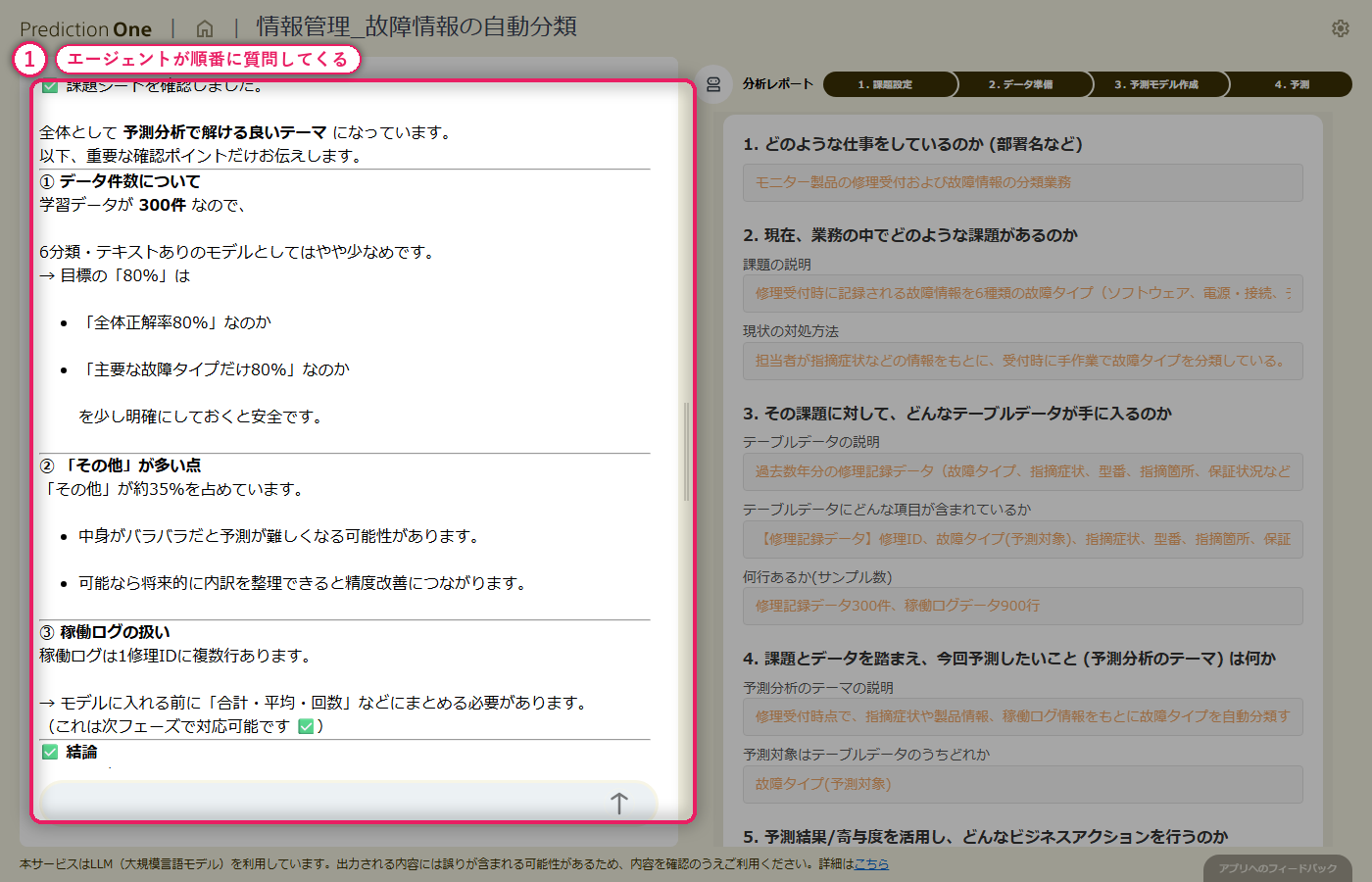
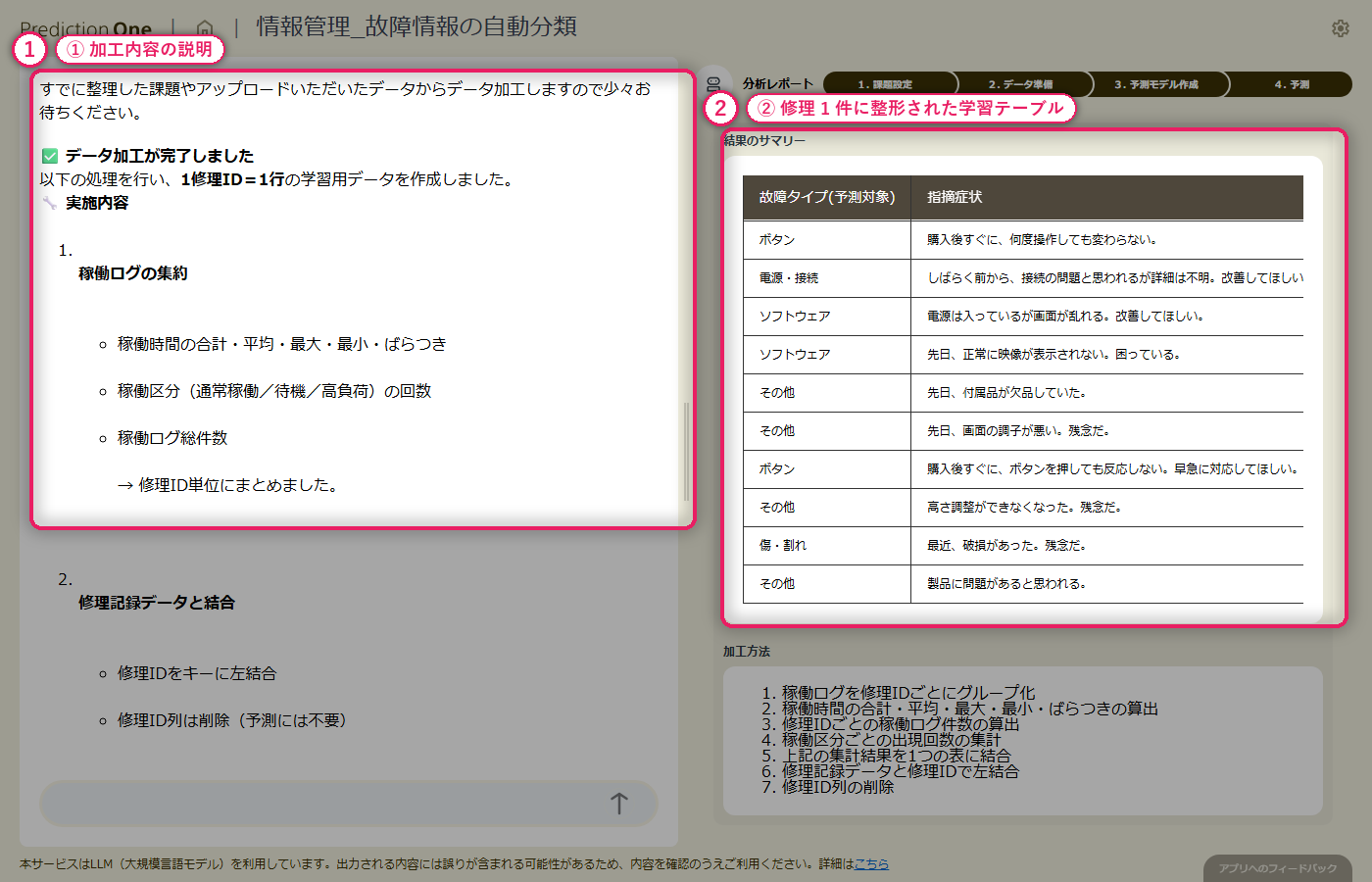
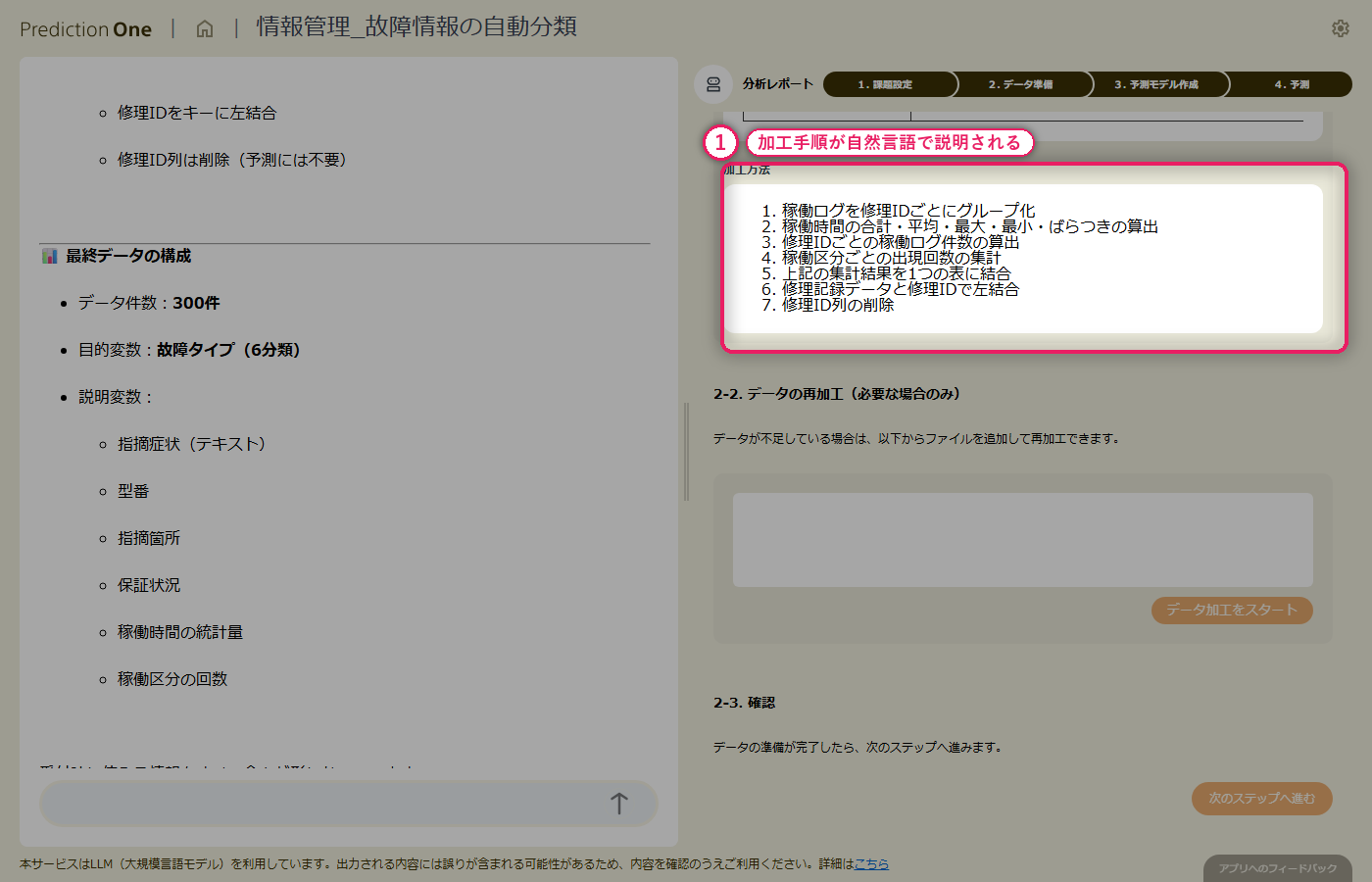
修理記録(A1)の1修理1行データに対して、稼働ログ(A2)の月次レコードから該当機器の直近数ヶ月分の稼働時間や稼働区分の統計量が自動で展開され、修理1件ごとの特徴量として横並びに整えられます。指摘症状のテキスト列はそのまま保持されるため、テキストと構造化数値が混在した学習テーブルが1ステップで用意できます。加工ロジックも自然言語で説明されるので、担当者が集計粒度や参照期間の妥当性をレビューできます。
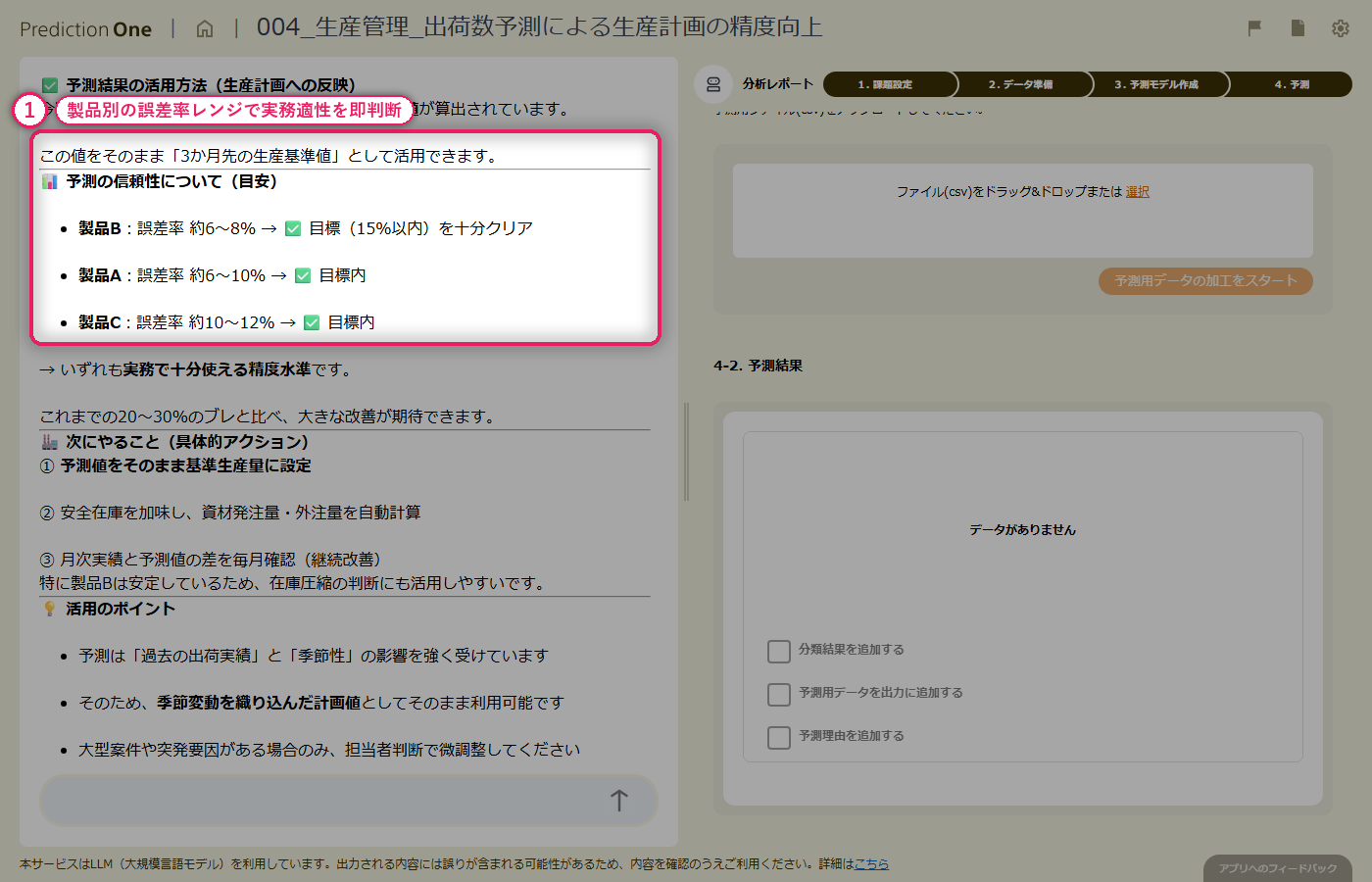
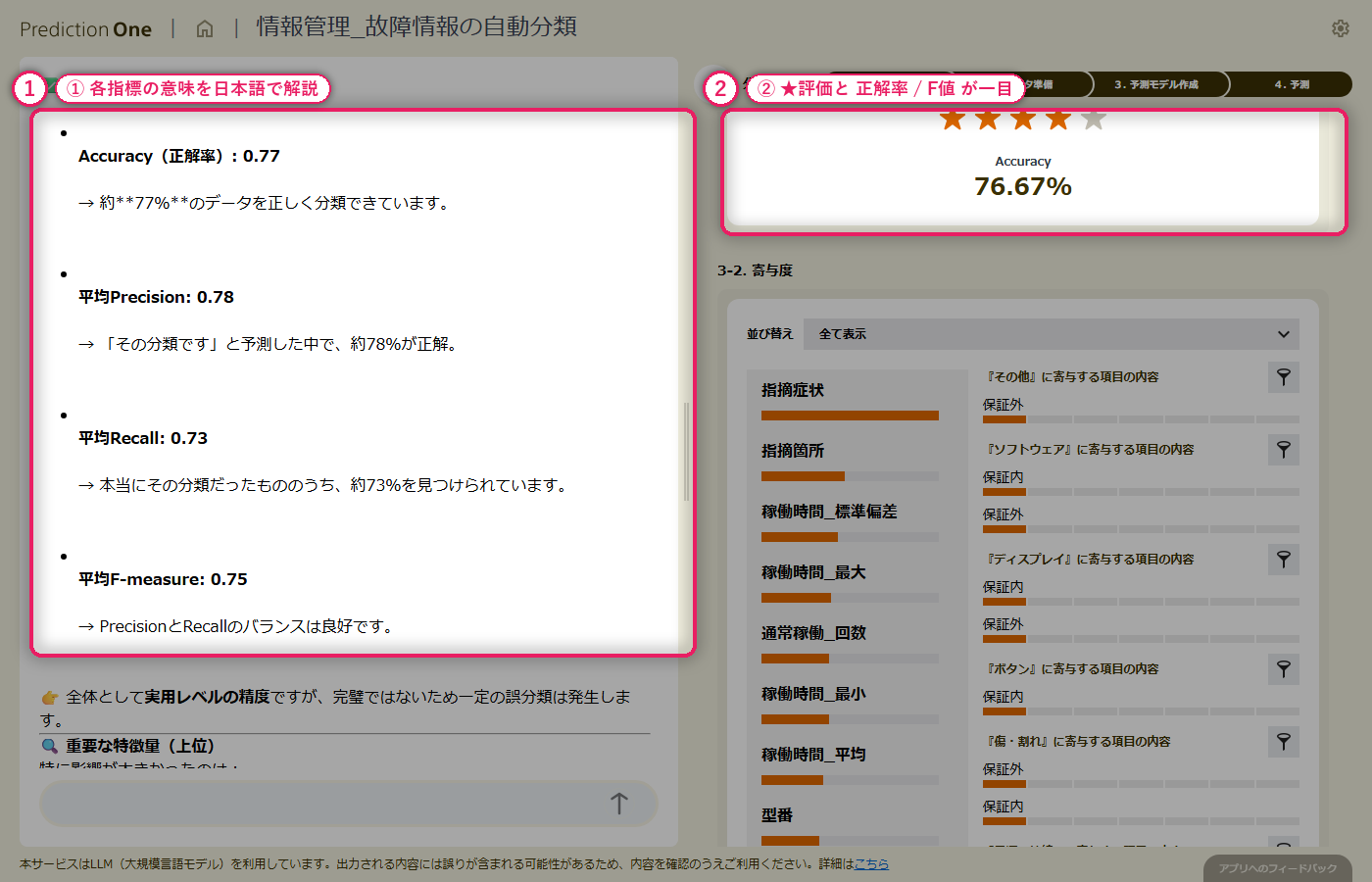
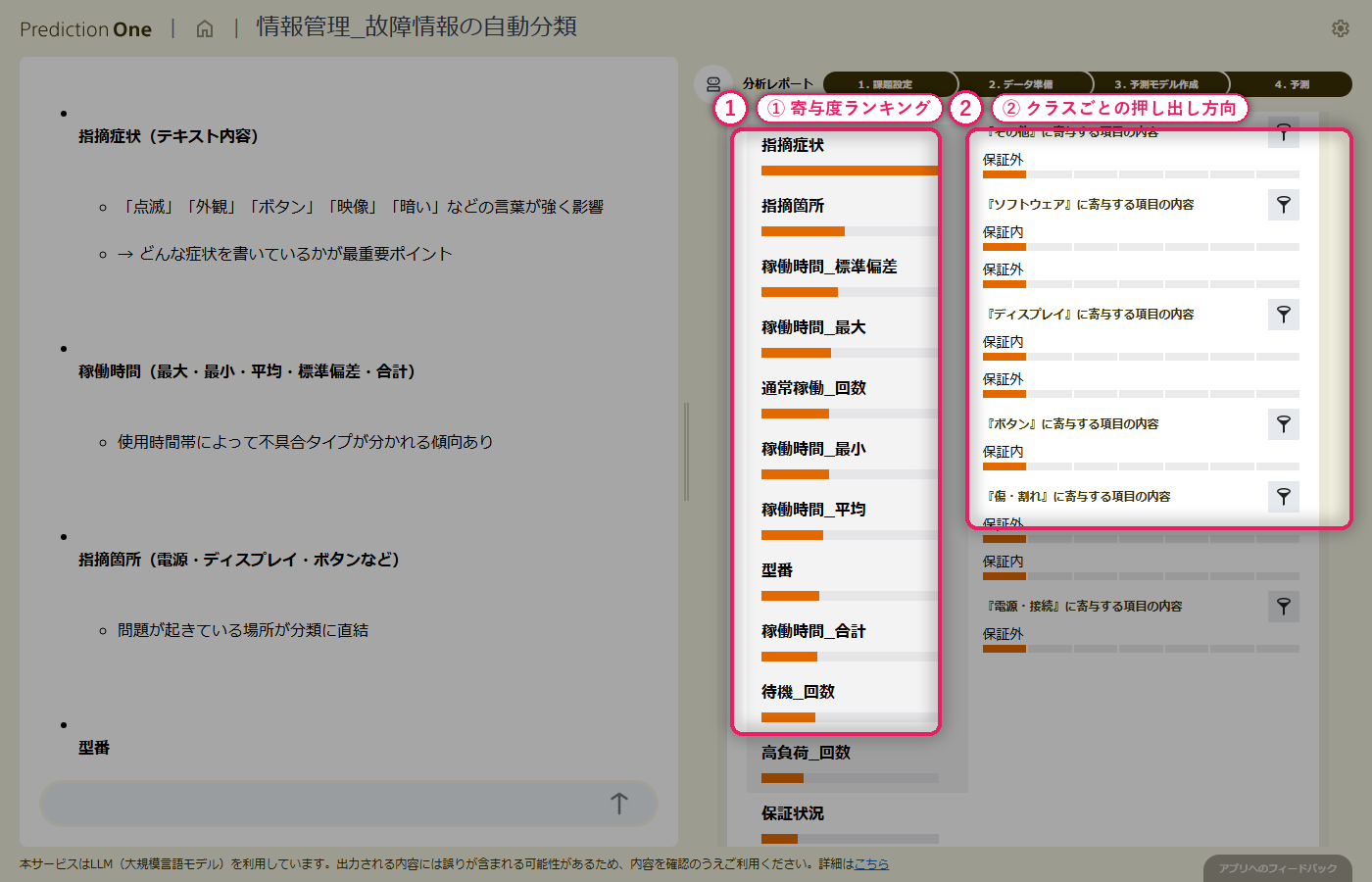
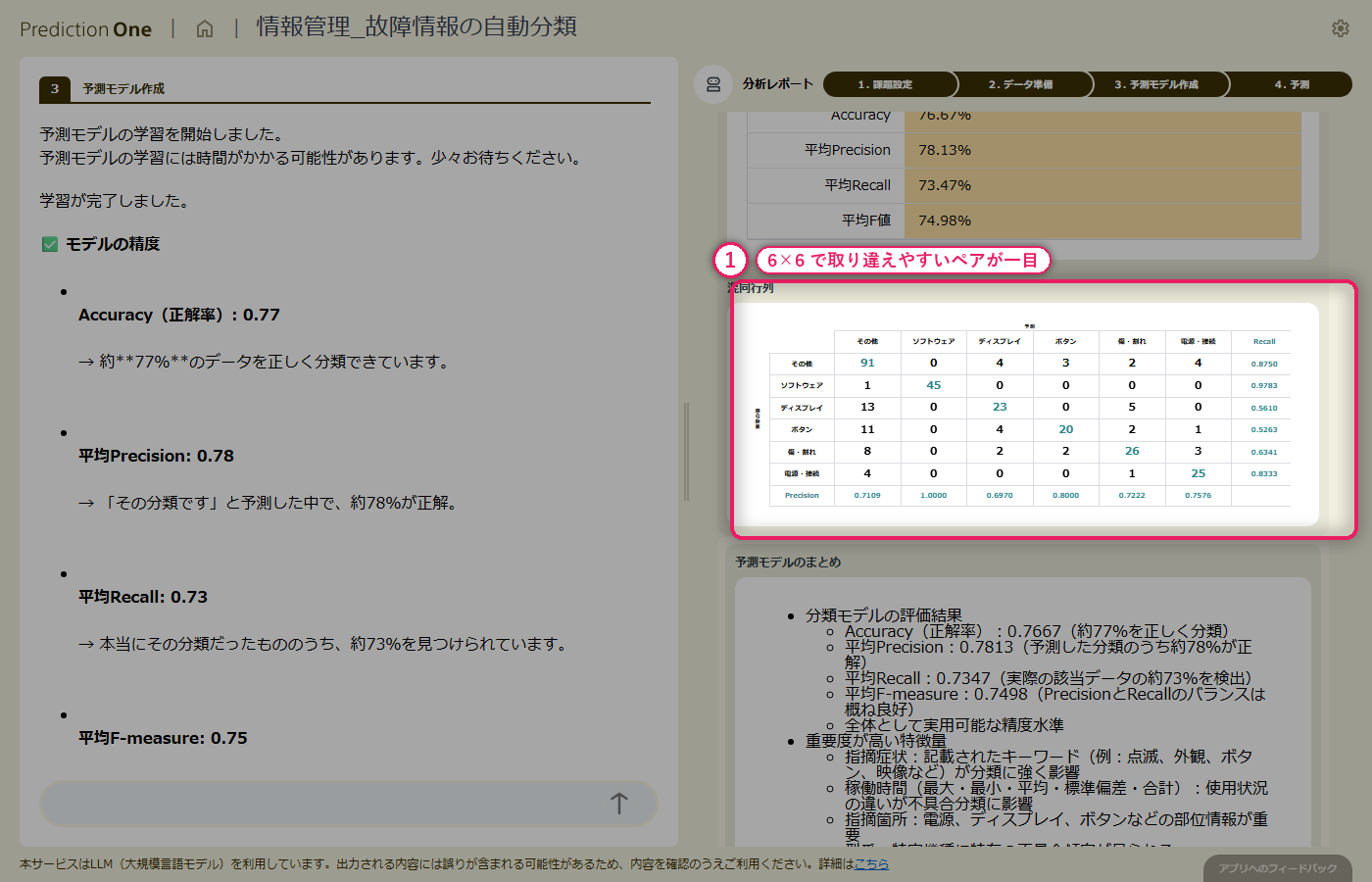
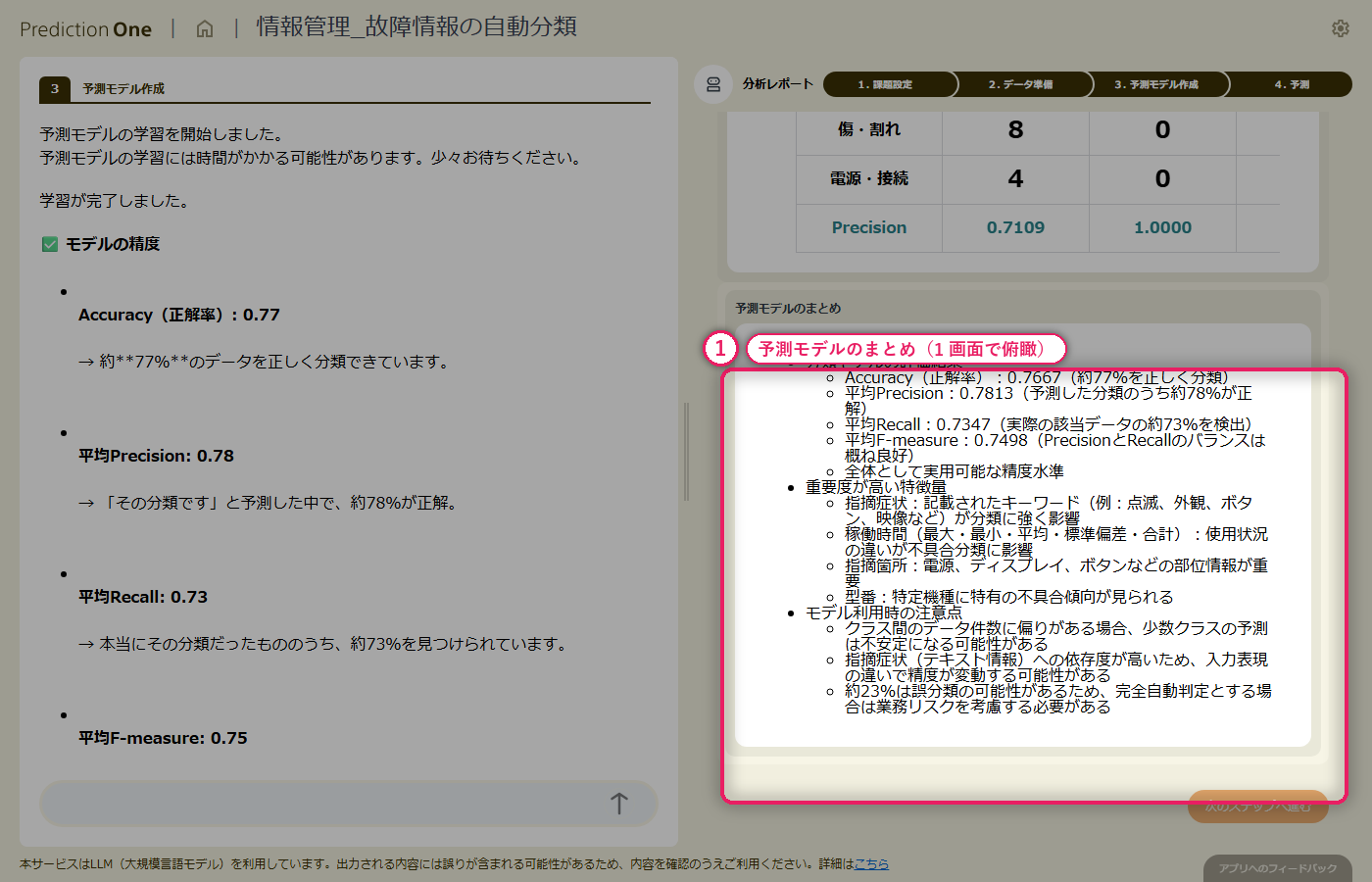
テキスト列と稼働ログの統計量を組み合わせた多値分類モデルを学習させると、正解率・平均 F値の水準評価が画面に出て、エージェントが「受付の一次振り分けとして実用できるかどうか」を日本語でコメントしてくれます。寄与度を見ると、指摘症状のテキスト由来の項目が大きなシグナルとして上位に並びつつ、稼働ログ由来の指標も食い込み、「テキストだけでは曖昧な症状を稼働状況が補完している」構造が読み取れます。混同行列では、どのクラスで取り違えが起きやすいかを 1 枚で把握できます。
Step 3 は 時間順ではなく、4 つの観点でモデルを確認します。
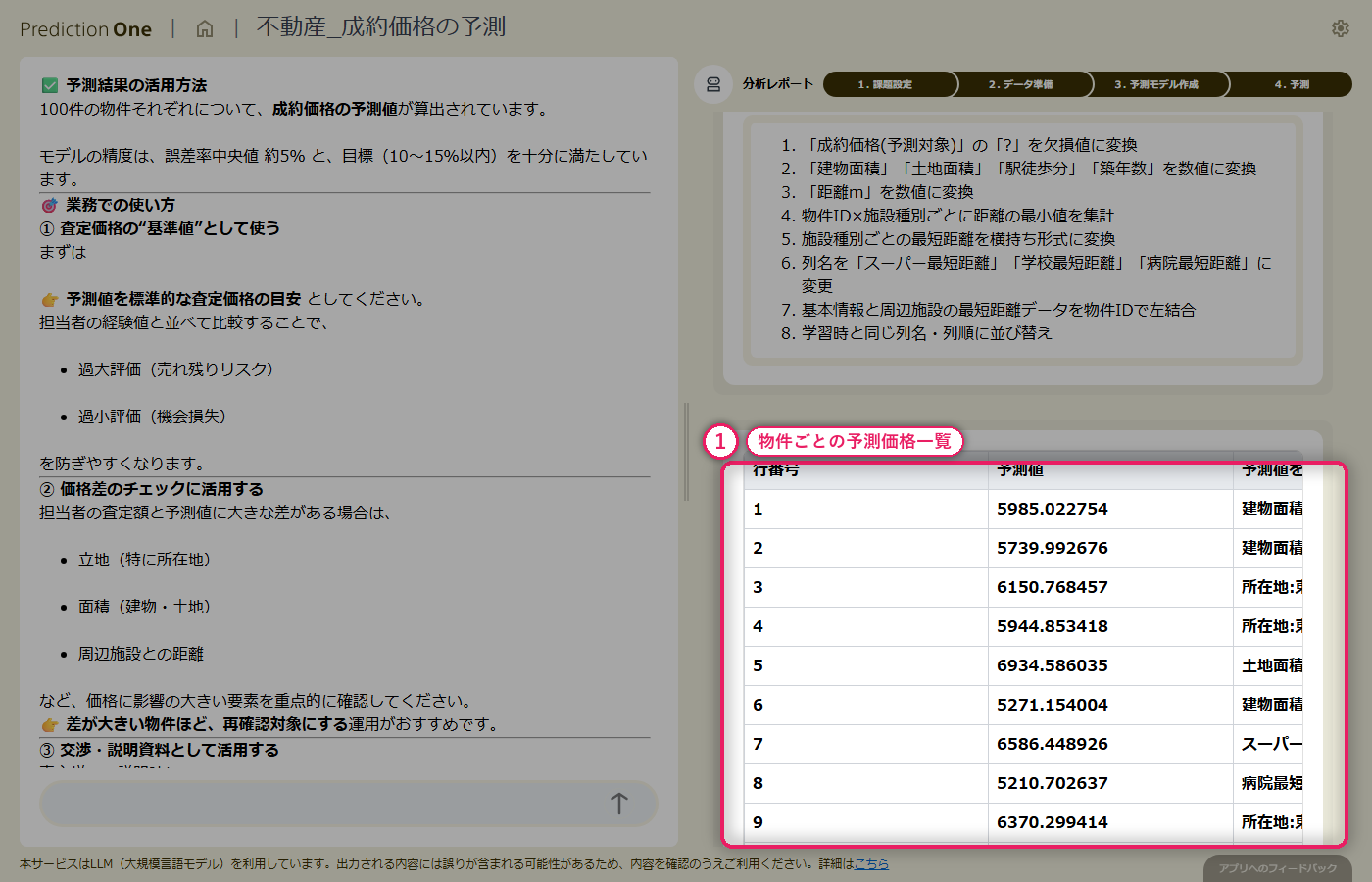
新規受付の修理記録(B1)と、対応する機器の稼働ログ(B2)をまとめて投入すると、修理案件ごとに 6 クラスの故障タイプ予測と各クラスの予測確率が得られます。予測確率の高い案件はそのままルーティングに、低い案件は人が確認する、といった切り分けが可能です。エージェントからは、予測結果を修理受付システムへ API 連携する案や、誤分類が集中しているクラスへの学習データ補強といった次アクションの提案も返ってきます。
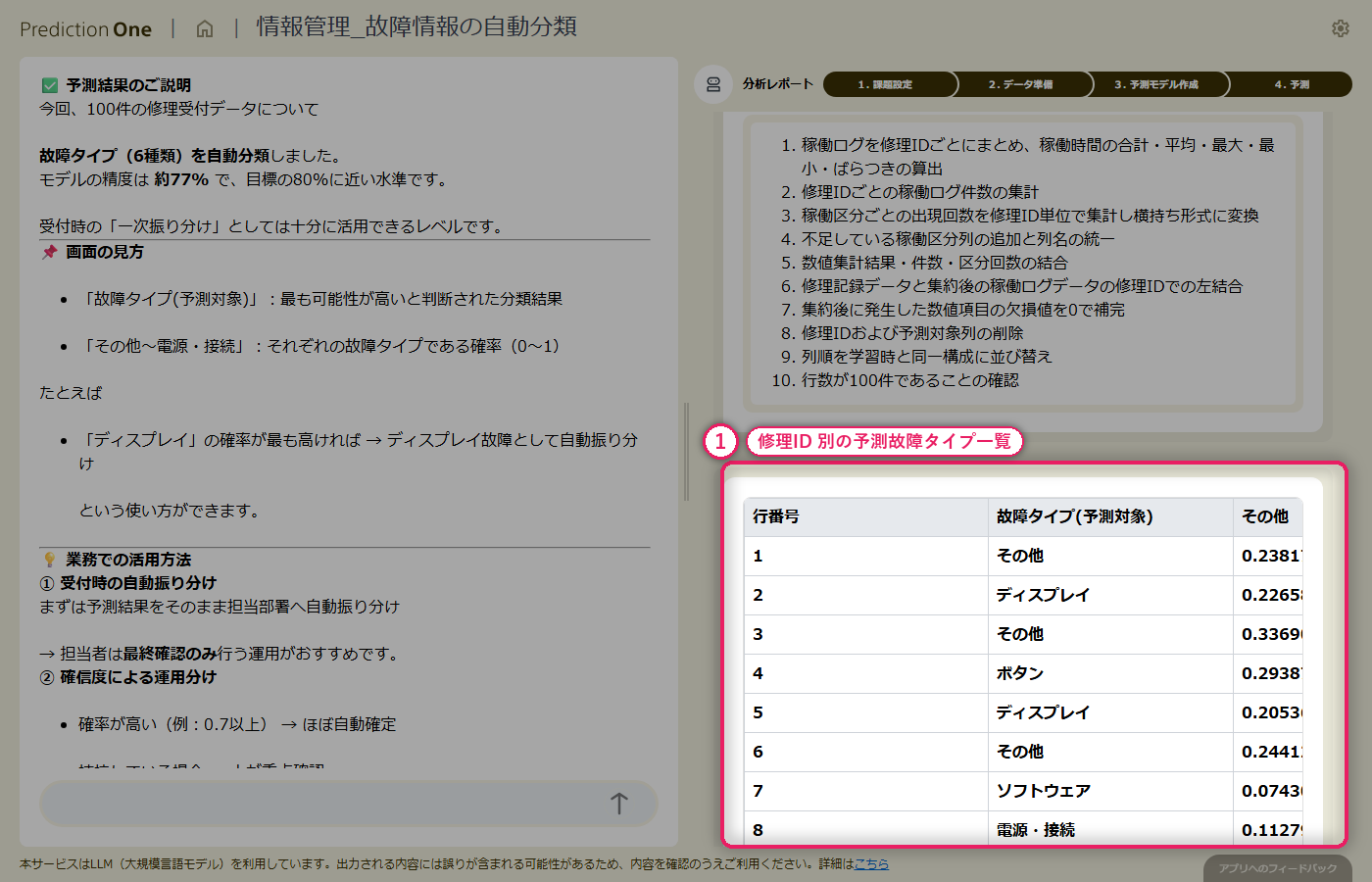
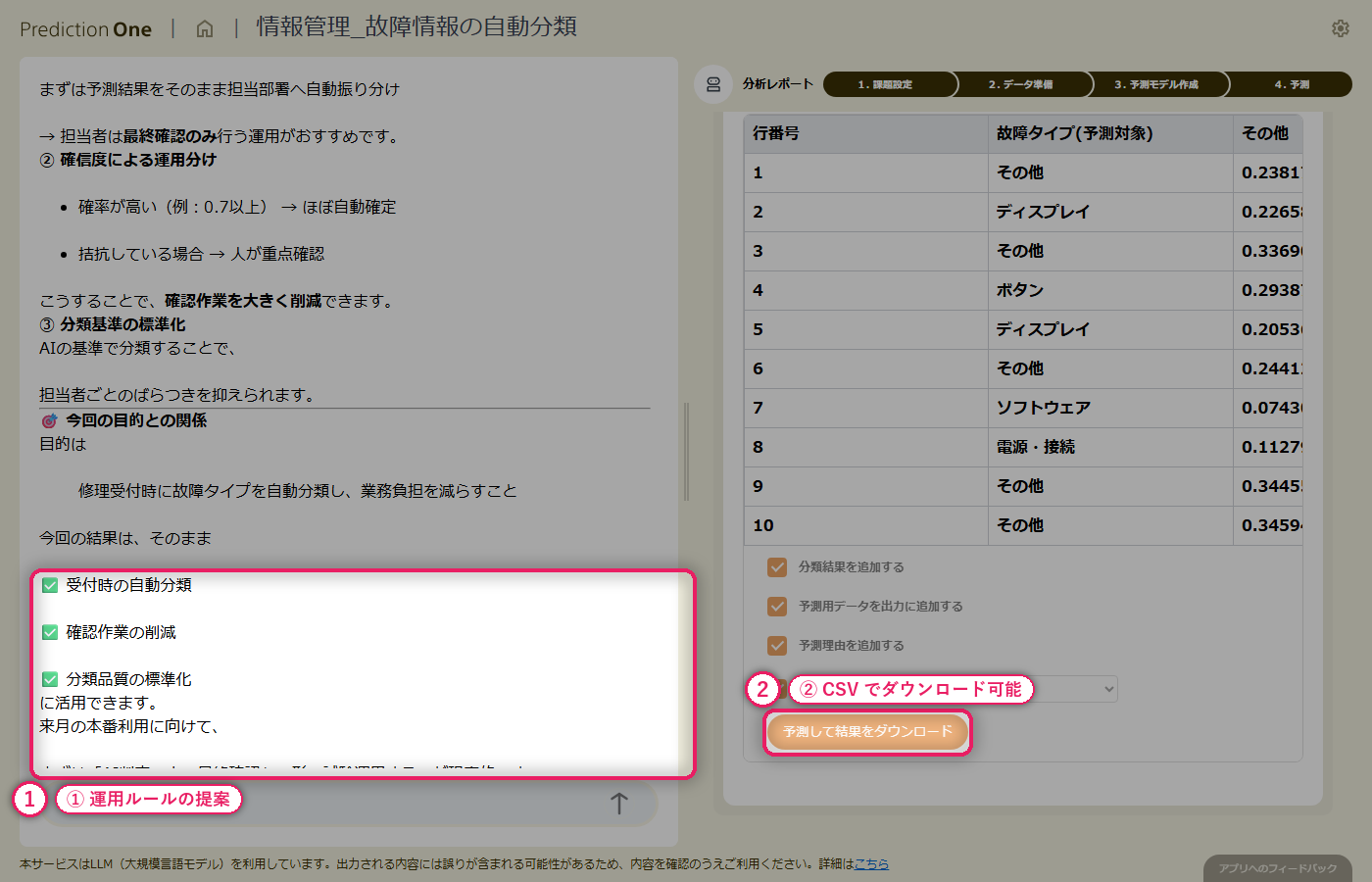
自由記述のテキスト列と、1機器あたり複数行ある稼働ログを組み合わせた多値分類モデルを、エージェントとの対話だけで構築できました。担当者の分類作業を補助する実用的なモデルに仕上がっています。
エージェントが出力する寄与度ランキングを見ると、指摘症状のテキストが大きなシグナルでありつつも、稼働時間の統計量など A2 由来の特徴量も上位に食い込みます。「単にテキストを読むだけでは見抜けない機器の使われ方」が分類に効いていることが分かり、テキストデータと構造化データを一緒に扱う業務では、このような「データを足す価値」が寄与度として可視化できます。