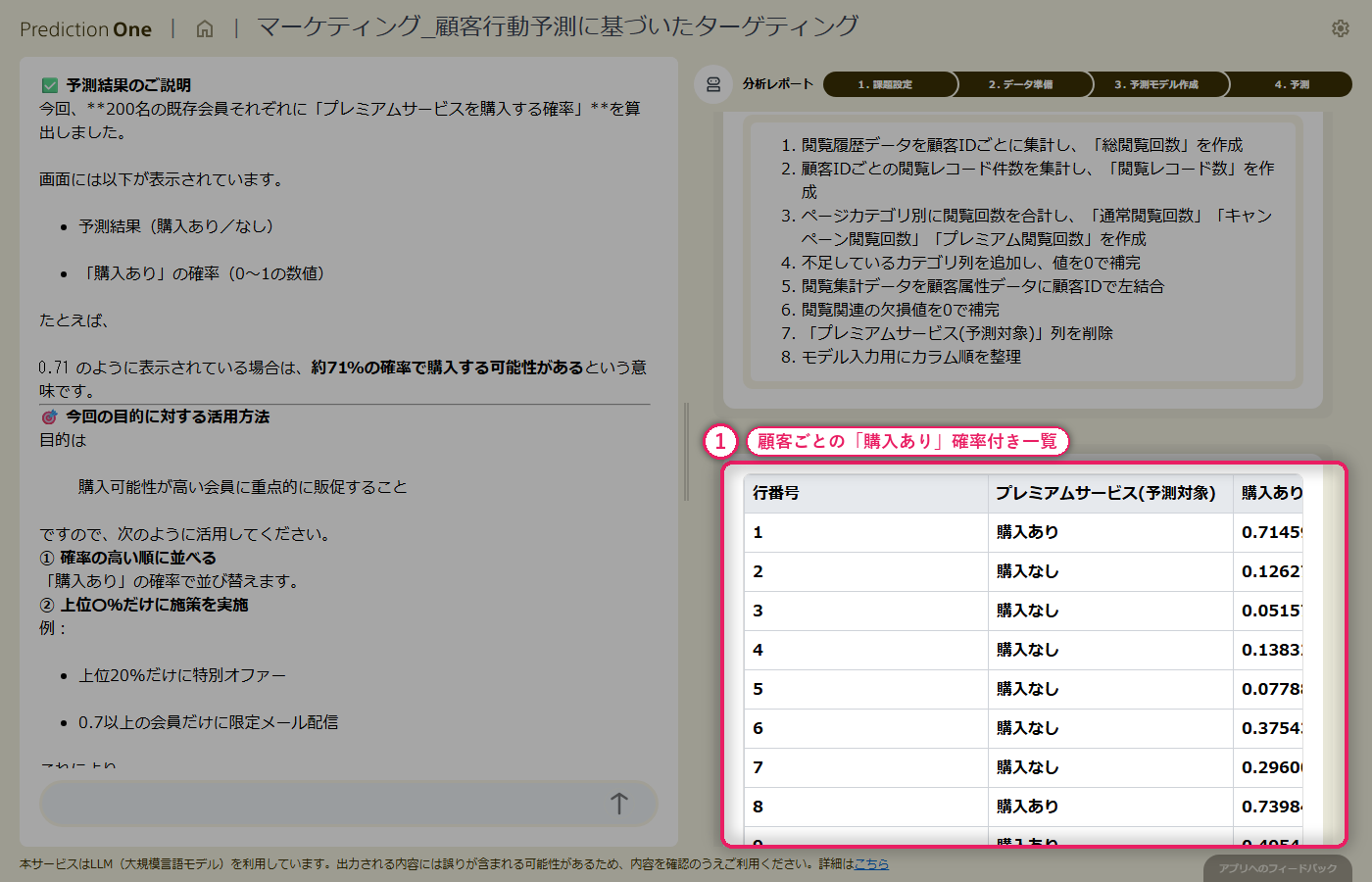
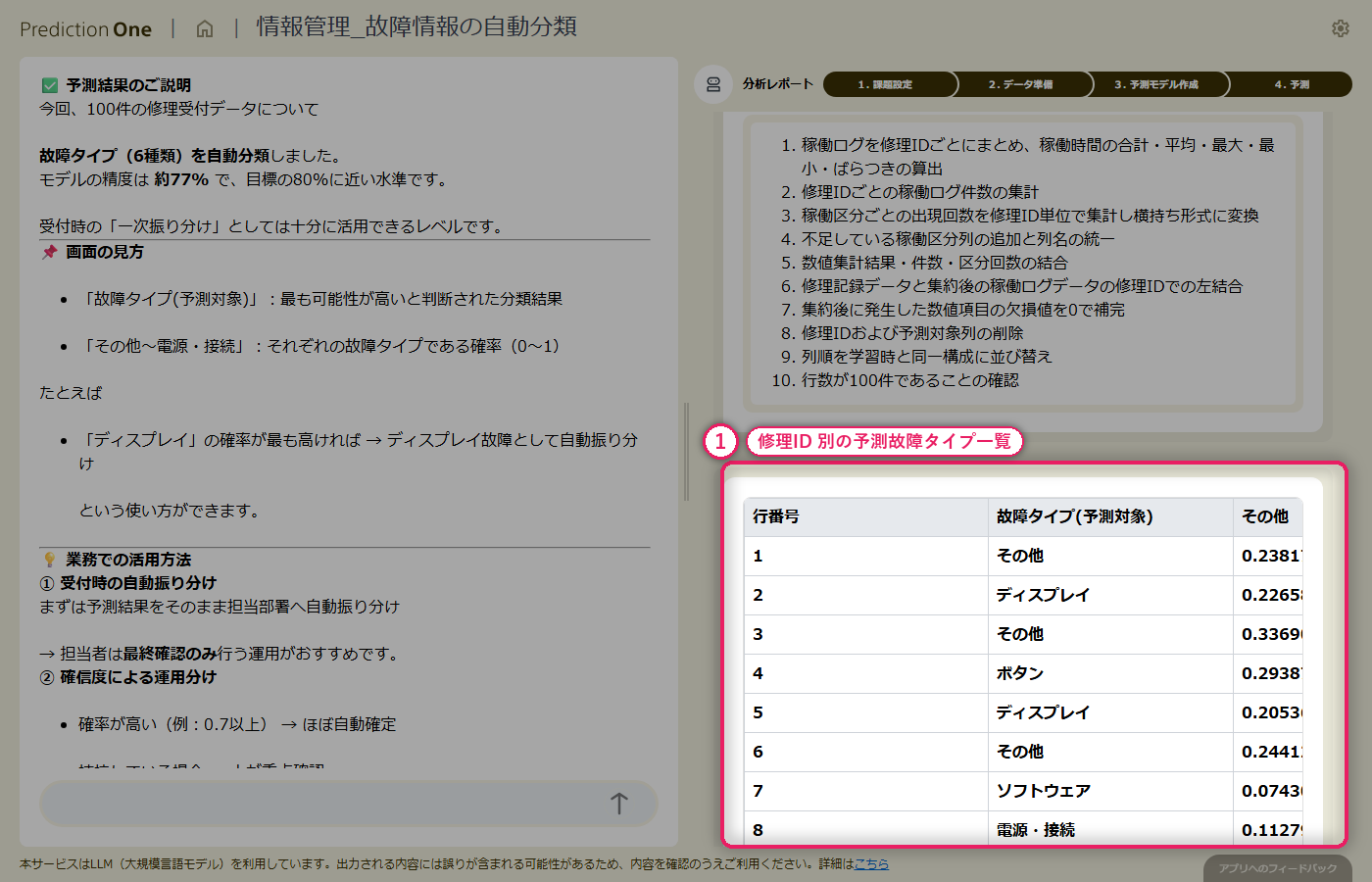
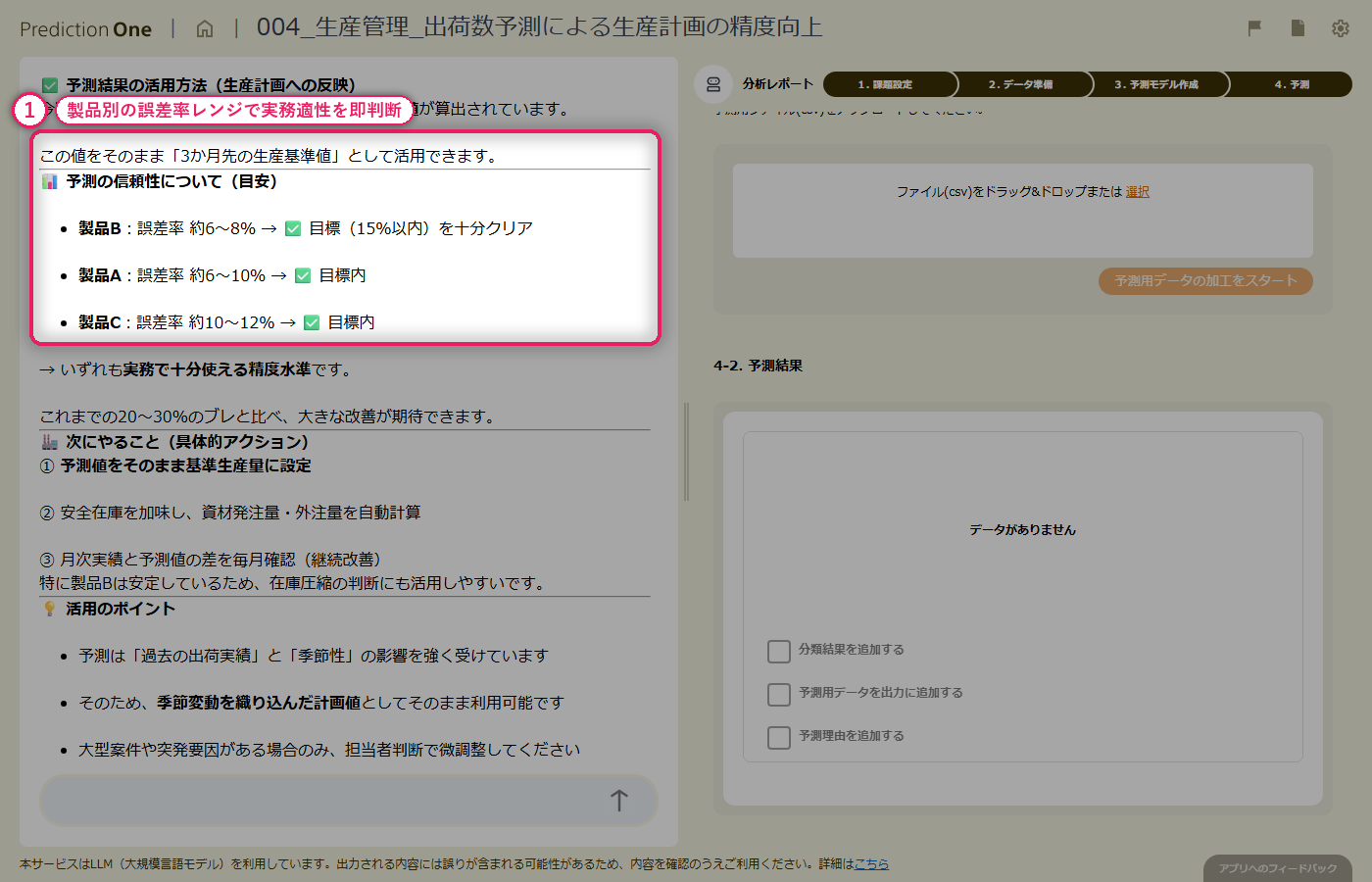
首都圏の一戸建て物件について、基本情報と周辺施設情報から「成約価格」を数値予測。複数テーブルをまたぐ数値予測モデルを、対話だけで構築します。
このチュートリアルでは、不動産仲介業者の立場で「一戸建て物件の成約価格を数値予測する」課題に取り組みます。経験則に頼りがちな価格設定を、エージェントと一緒に作る客観的な数値予測モデルで裏付けるシナリオです。
物件の基本情報(建物面積・土地面積・駅徒歩分・築年数・所在地など)に加えて、周辺施設情報(スーパー・学校・病院までの距離)というサブデータも活用します。1物件に複数行ある施設データは、エージェントが自動で集計・結合してくれるため、Excel でのデータ加工は不要です。
最終的に、担当者の感覚で決めた価格と予測価格を突き合わせて、乖離の大きい物件を振り返る、という業務シナリオを体験できます。
背景:「成約価格は担当者の経験頼みで、価格設定にブレがある。客観的な価格予測ができれば、価格提案と顧客説明の精度が上がる」という課題に対し、過去の成約データを使って数値予測モデルを構築します。
東京23区・東京都下・神奈川・埼玉・千葉の一戸建て物件のデータをもとに、まずは基本情報だけで予測モデルを作り、そこに周辺施設の距離データを加えると精度がどう変わるかを確認します。スーパーの近さが価格にどの程度効いているか、といったインサイトも寄与度から読み取れます。
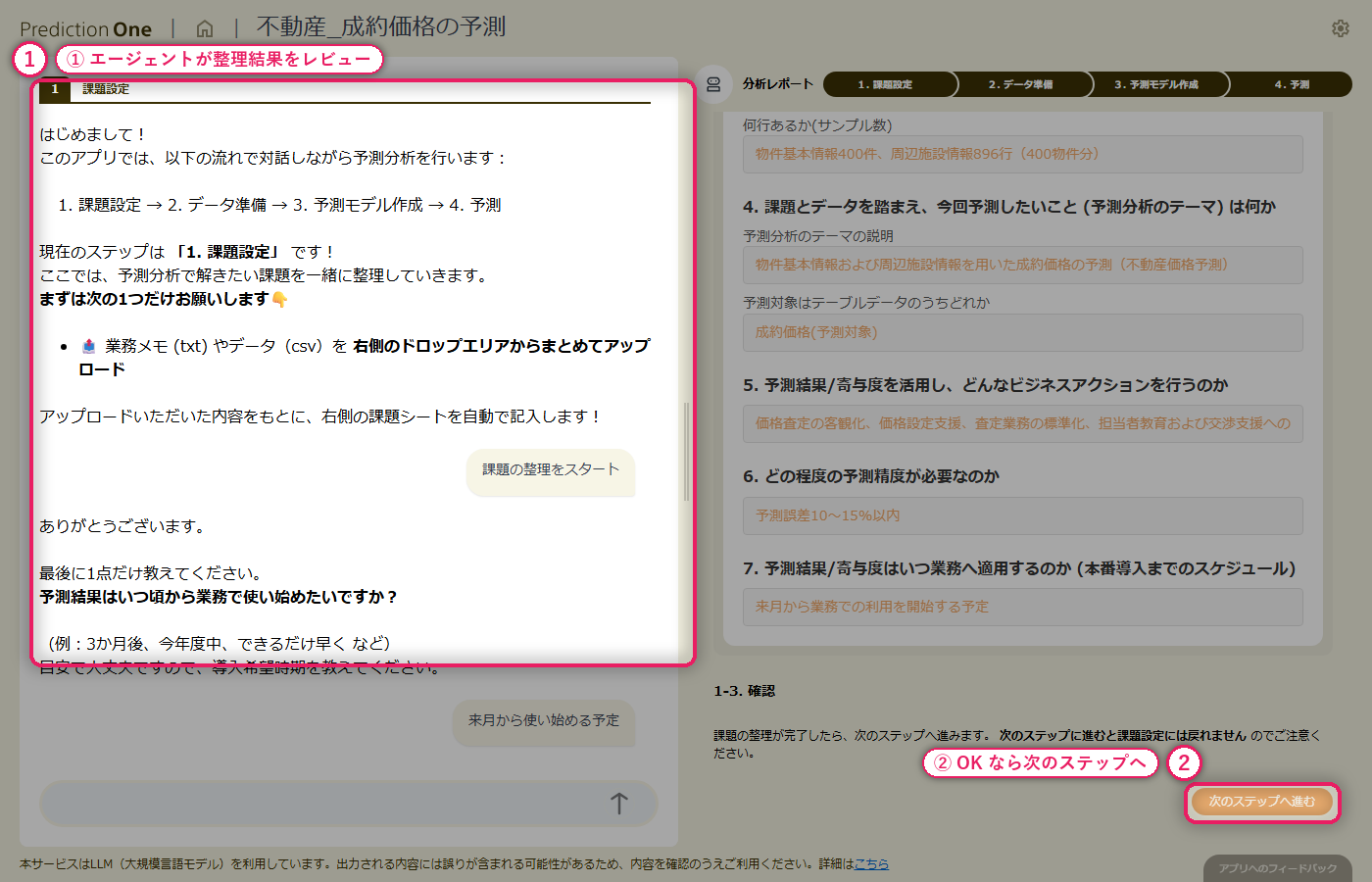
A0(成約価格予測の業務説明)と、物件基本情報(A1)・周辺施設情報(A2)の学習用ファイルを投入します。エージェントは 1 物件 1 行のテーブルと 1 物件複数行のサブテーブルを自動で見分け、物件 ID 単位で成約価格を当てる数値予測タスクとして課題シートを組み立てます。ヒアリングでは、目的変数を成約価格に固定すること、周辺施設の距離データをどう集計して取り込むかといった論点が対話形式で確認されます。
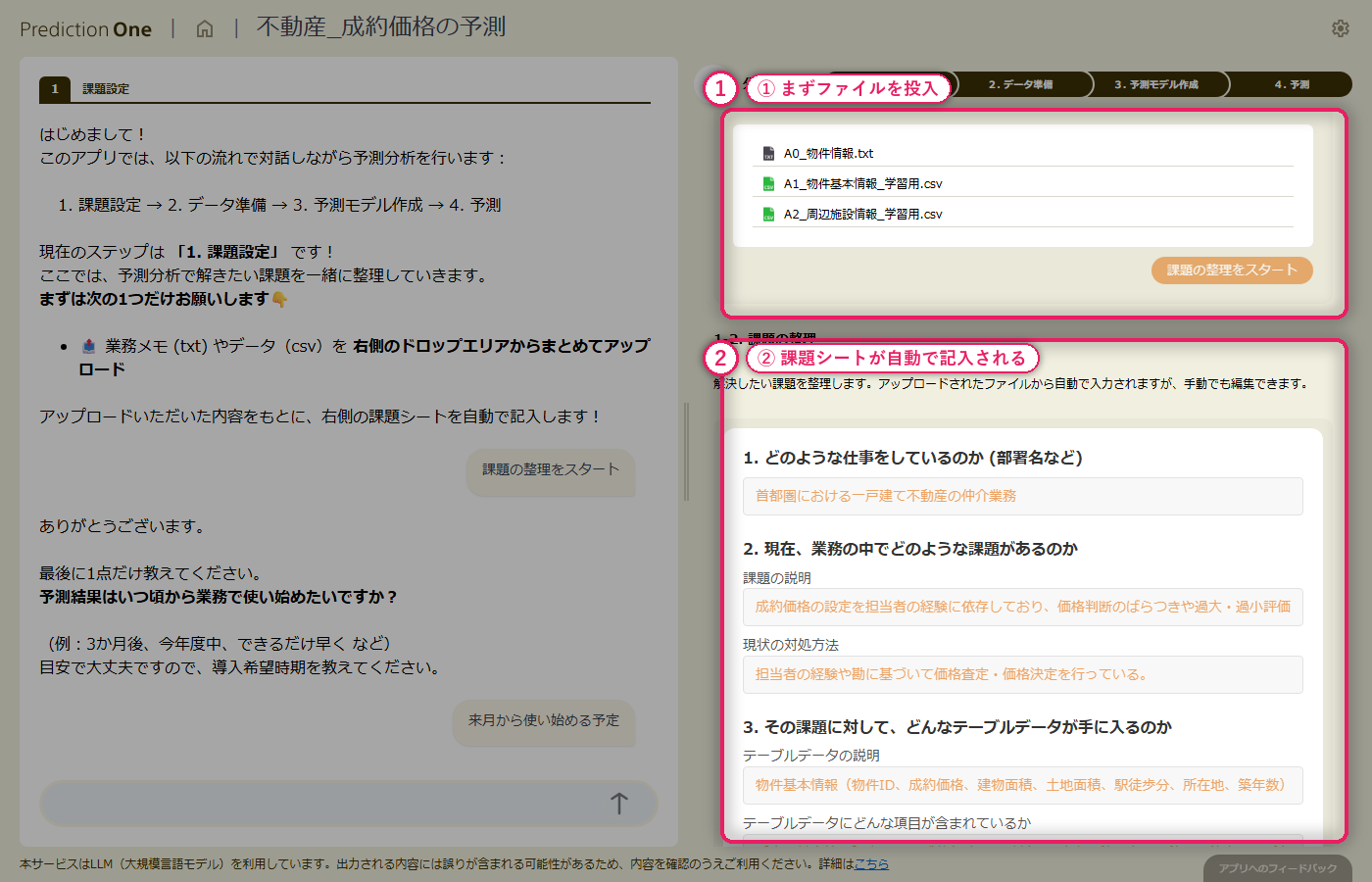
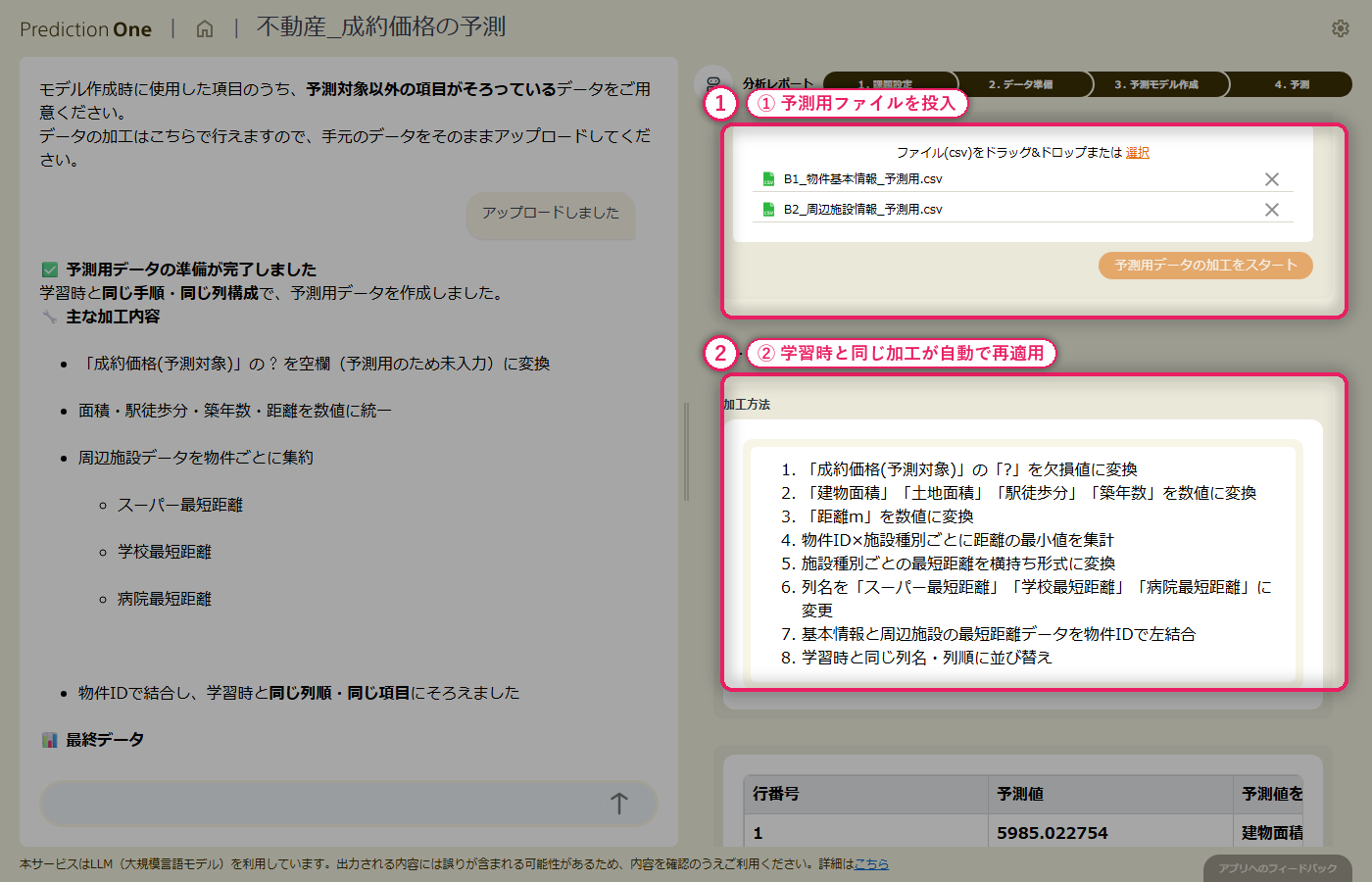
A0_物件情報.txt と学習用の物件基本情報・周辺施設情報を投入すると、エージェントが「物件ID で結合して成約価格を当てる数値予測タスク」として自動認識し、課題シートに初期値を書き込みます。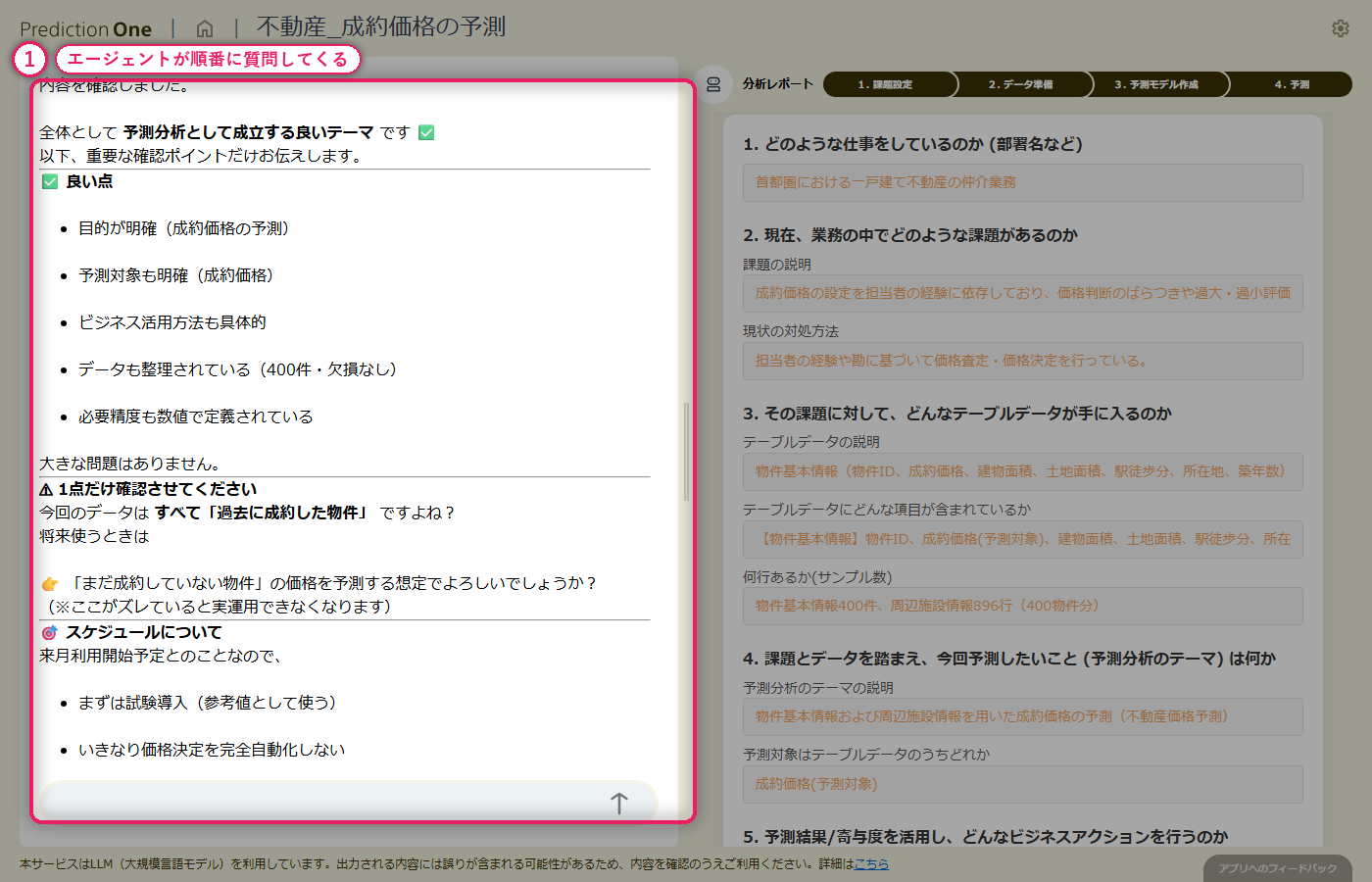
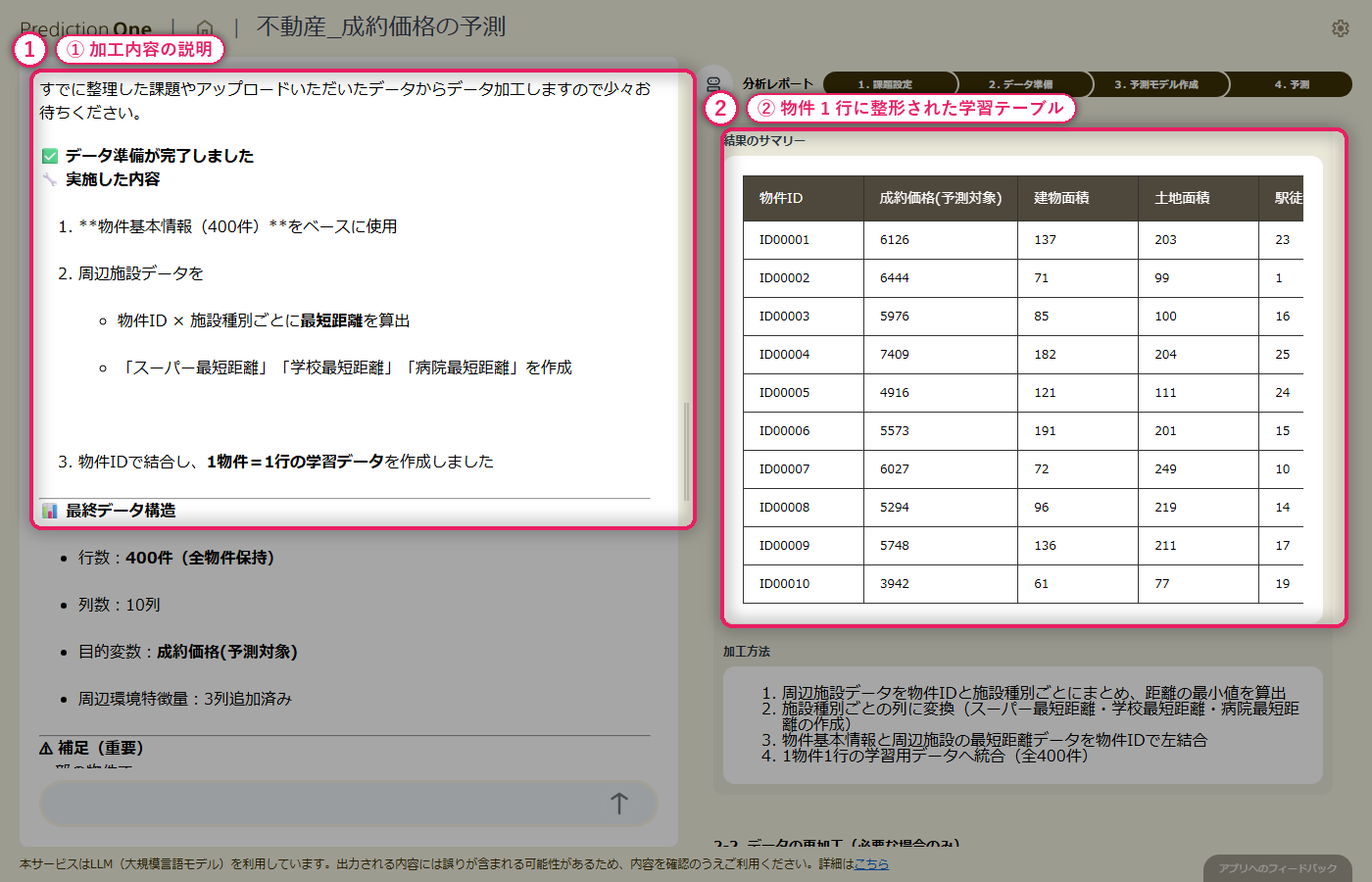
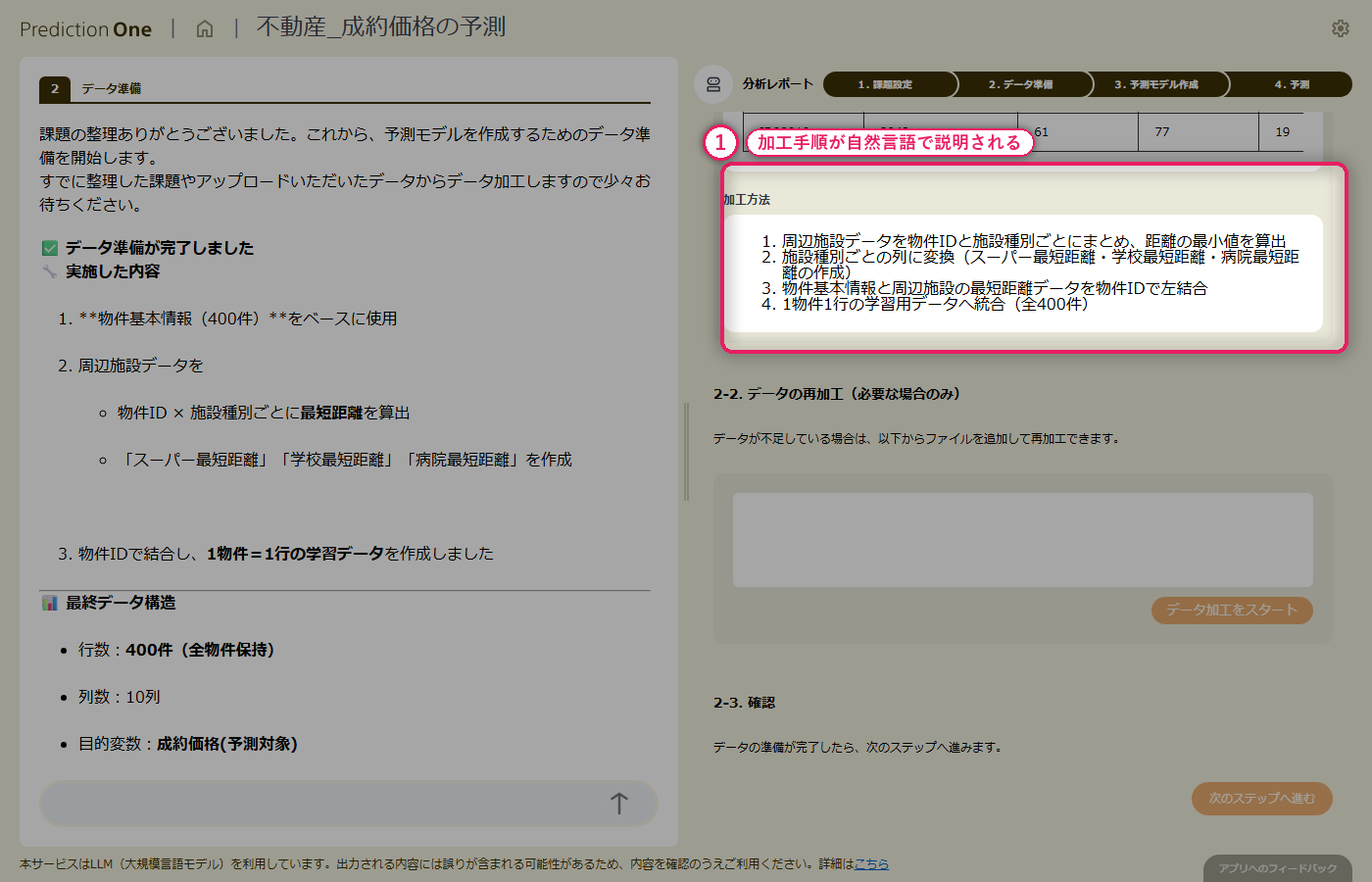
物件基本情報(A1)の1物件1行データに対して、周辺施設情報(A2)の複数行レコードから、スーパー・学校・病院などの最寄り施設までの距離や平均距離が自動で集計され、物件ごとの特徴量として横並びに展開されます。駅徒歩分や建物面積といった基本特徴量と、周辺施設までの距離という生活利便性を示す特徴量が、1つの学習テーブルに統合されます。加工内容も自然言語で説明されるため、集計ロジックの妥当性を業務担当者がレビューできます。
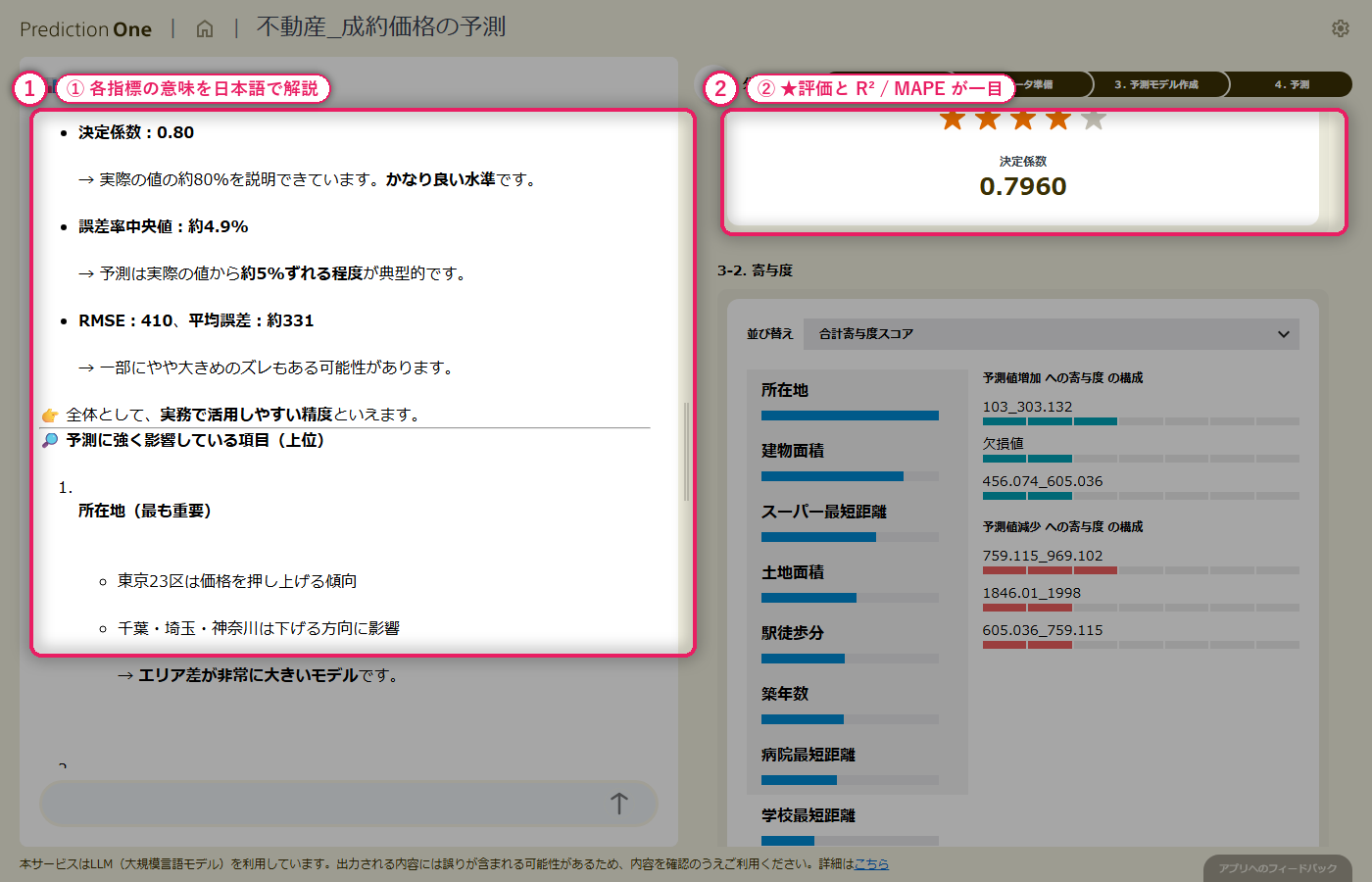
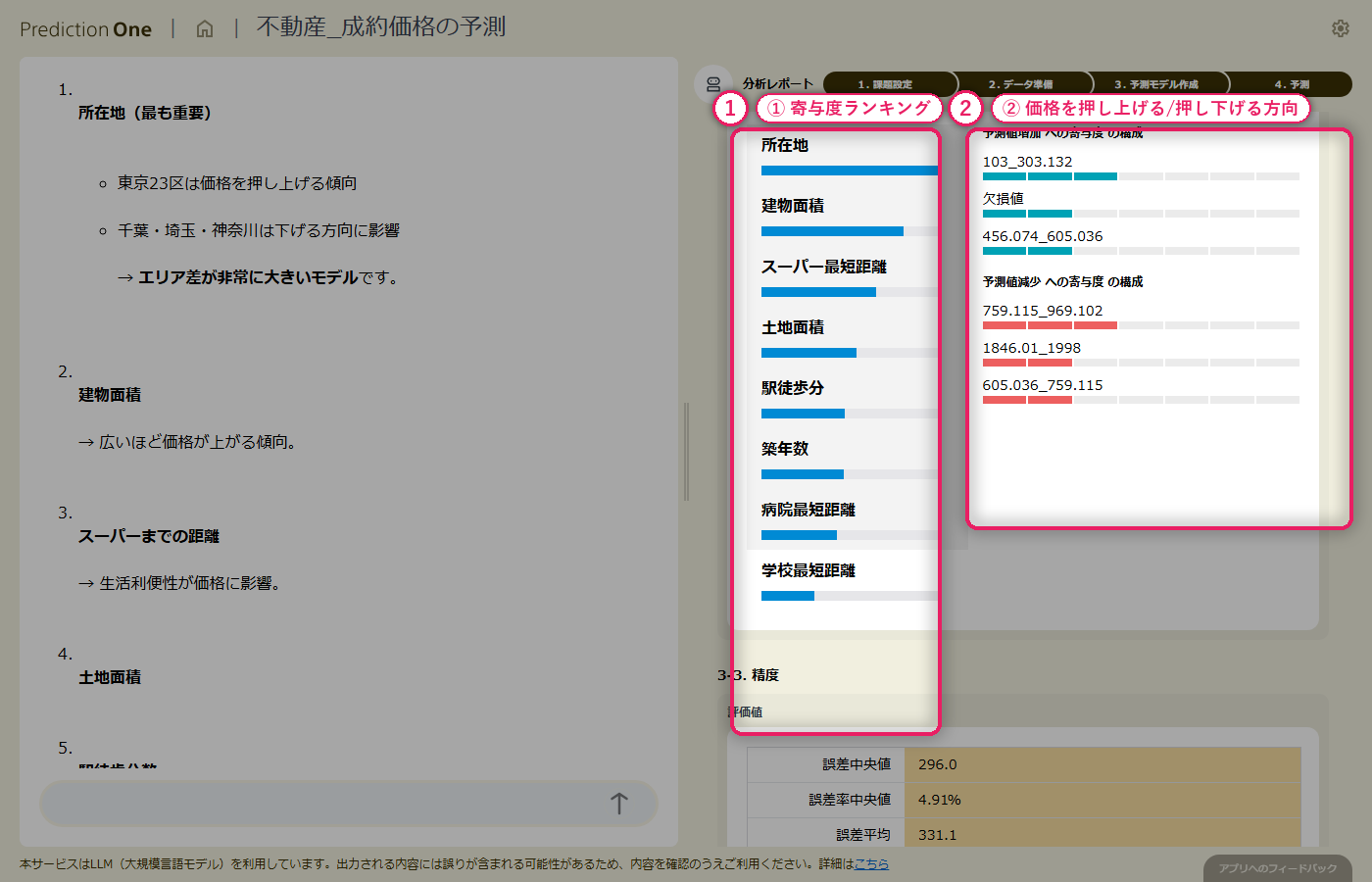
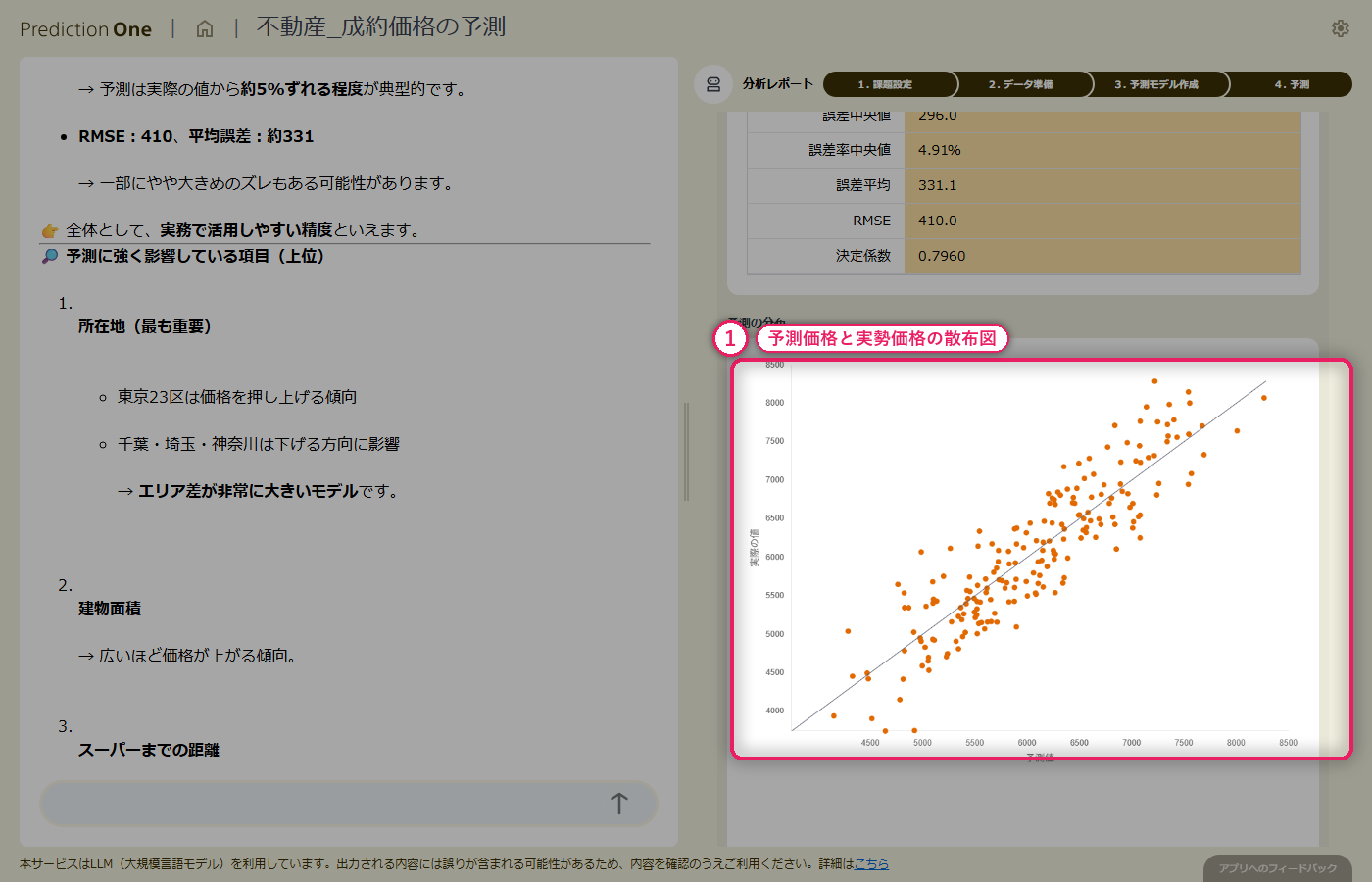
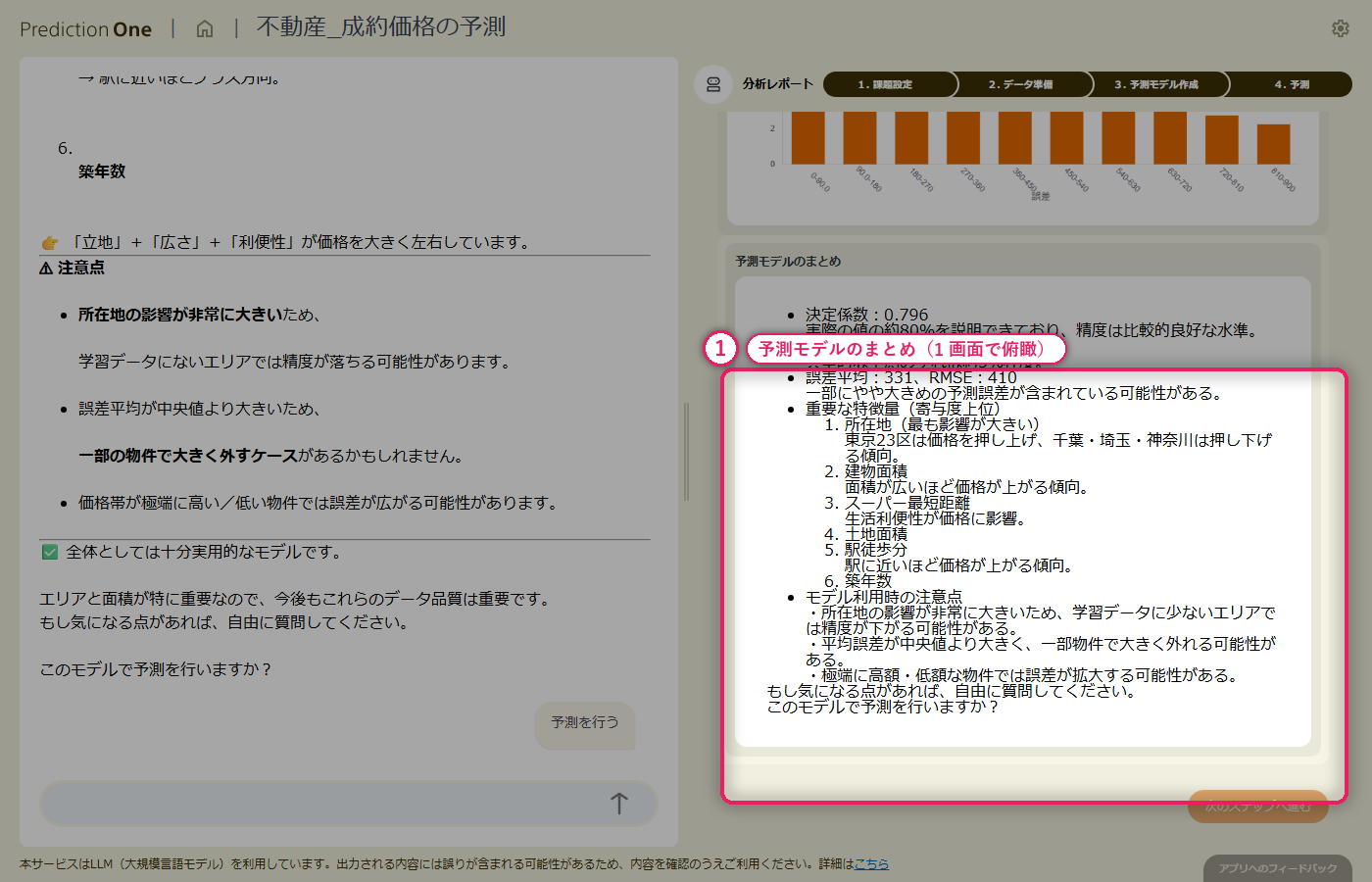
基本情報と周辺施設情報を結合した学習テーブルから数値予測モデルを学習させると、決定係数と誤差率中央値の水準評価が画面に出て、エージェントが「価格提案の裏付けに使えるかどうか」を日本語でコメントしてくれます。寄与度を見ると、建物面積や築年数といった基本項目に加えて、周辺施設までの距離も上位に入り、「駅徒歩分だけでは測れない生活利便性」が価格形成に寄与していることが読み取れます。予測と実績の散布図では、どの価格帯で予測が当たりやすく、どこで外れやすいかの傾向も把握できます。
Step 3 は 時間順ではなく、4 つの観点でモデルを確認します。
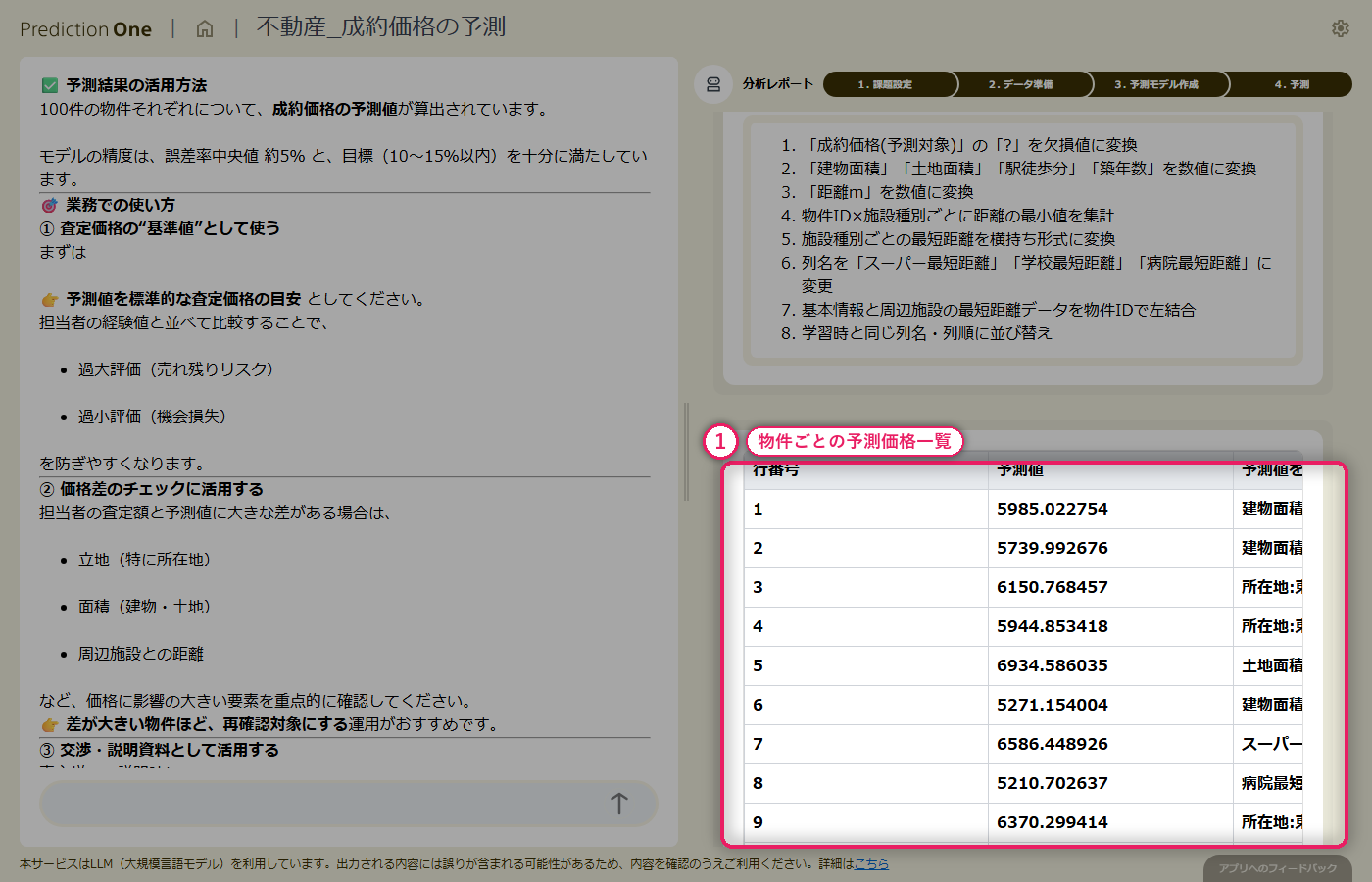
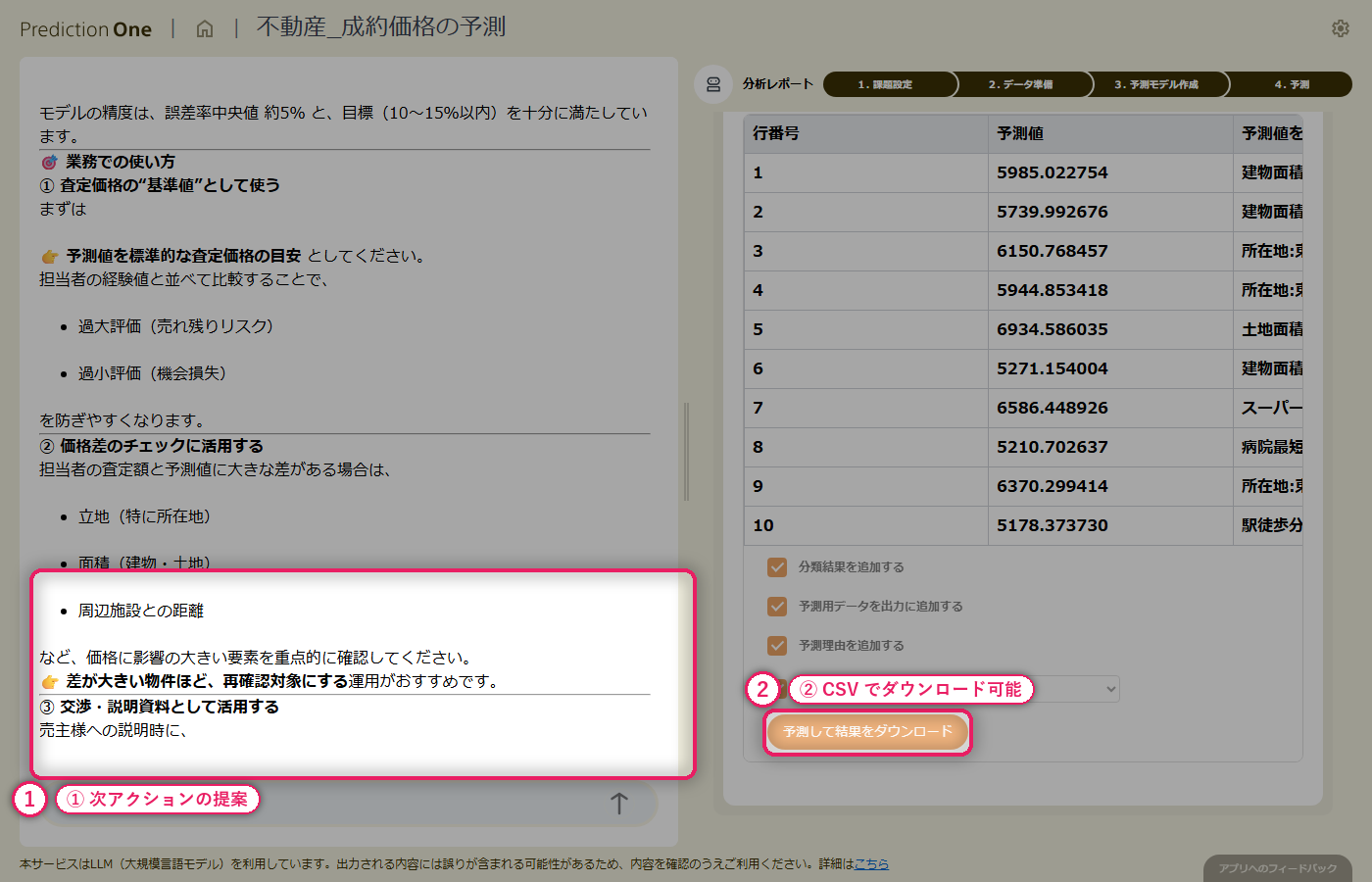
予測用の物件基本情報(B1)と周辺施設情報(B2)をまとめて投入すると、物件ごとの成約価格予測が一覧で得られます。担当者の感覚で決めた価格と予測価格を突き合わせて、乖離の大きい物件を洗い出せば、価格設定の妥当性を客観的にレビューできますし、顧客への説明時にも「相場に対してこの物件がどう位置付くか」を根拠付きで示せます。エージェントからは、乖離が大きい物件に対する追加調査や価格見直しといった次アクションの提案も返ってきます。
物件の基本情報と周辺施設情報という 2 つのテーブルを結合し、成約価格を当てる数値予測モデルをエージェントとの対話だけで構築できました。担当者の価格設定を裏付ける数値予測モデルに仕上がっています。
エージェントが出力する寄与度ランキングを見ると、周辺施設(A2)由来の距離特徴量が上位に入り、駅徒歩分だけでは測れない「生活利便性」が価格に効いている様子が可視化されます。このインサイトは、経験則では説明しきれなかった部分を言語化する助けになります。